I’d love to get this conversation going again! Fully onchain websites powered by ENS would be so great.
1 Like
Under the interpretation that the contenthash is “how to render my ENS as a website”:
I’m a fan of having two codecs:
(1) URL
uvarint(codec1) + <url as utf8 bytes>
(RFC-3986 might not be necessary, as the gateway or client still has to parse it, and no restrictions makes it future proof)
(2) Data URL
uvarint(codec2) + byte(length mime) + <mime bytes as ascii> + <bytes of data>
As a URL:
(1) is literal
(2) is data:$MIME;base64,${btoa($DATA)}
As a website: https://$NAME.limo/$PATH
(1) HTTP 307 + [Location: $URL/$PATH]
(2) HTTP 200 + [Content-type: $MIME, Content-Transfer-Encoding: binary] + $DATA
Note: $PATH is ignored (see below)
Note: The gateway would likely put limits on how big of a file you can serve.
.limo already supports this, but gateways should be encouraged to support ENSIP-10 and enable CCIP-Read.
Example: "https://raffy.chainbound.eth.limo"
→ contenthash("raffy.chainbound.eth")
→ evm-gateway to Base Mainnet
→ (2) text/html <html>chonk</html>
→ HTTP 307
→ see "chonk" in browser
(2) is still pretty limited as it can only host a single file but I think that’s a good start.
An IPFS contenthash allows vitalik.eth/a/b. Possible solutions:
- Reversed path components as namespace:
b.a.vitalik.eth - Resolver profile:
vitalik.eth/a/b→website("vitalik.eth", "a/b")
As I mentioned above, I plan to submit an update to ENSIP-7 which includes all the protocols with examples and links.
2 Likes
After thinking about this some more, we should clarify this part of the protocol too.
.limo and others do a good job of translating https://$NAME.limo/$PATH into httpURLFromContenthash(resolver.contenthash($NAME)) + $PATH
where $PATH is /path + ?querystring
This is not specified in ENSIP-7 nor are there examples like https://[vitalik.eth].limo/[general/2022/12/05/excited.html]
For (1) URL — the HTTP 307 should append the $PATH.
For (2) Data URL — contenthash() doesn’t have an additional parameter to supply the $PATH when the contenthash codec supports it.
Maybe? we need a third option (3) which is just <uvarint(codec3)> and this indicates that to resolve the contenthash, you call a new function: contenthash(bytes32 node, string calldata relativeURI, bytes memory context) with CCIP-Read enabled.
GET https://raffy.eth.limo/chonk?moo → contenthash("raffy.eth","/chonk?moo", bytes("http.get"))
Or instead of a placeholder contenthash, if supportsInterface(IHTTPResolver), you never call contenthash() and instead call something like http(bytes32 node, string calldata method, string calldata relativeURI).
Having a field for data URIs or dynamic content is not unreasonable. Putting either in a field named contentHash is a very bad idea IMO. contentHash has a very clear meaning, which is that it represents the hash of an immutable asset. Anything dynamic (mutable) or not-a-hash (data URI) is simply not a content hash and shouldn’t be put in that field.
2 Likes
After reading the specification, it seems that this isn’t proposing the addition of dynamic content. Recommend changing the terminology used throughout this post to make it clear that the content you are proposing is not dynamic, it is encoded directly into the field.
(note: I still disagree that anything other than a content hash should be put in a field called content hash)
1 Like
contenthash does have the word “hash” in it, but my understanding is that it’s inspired from Multihash which is just a container-spec for hashes. Since contenthash is not fixed-length, any data (eg. an URL) is technically a hash under identity: h(x) = x. Additionally, there is no requirement that contenthash (or any value) is static.
See this comment regarding the purpose of contenthash, specifically:
Adding new profiles is a lengthy process. contenthash(), text(key), and addr(coinType) already exist. And technically, these are all the same thing and can be emulated from a single get(bytes) returns (bytes) profile.
The point is: with evm-gateway, we can bridge content straight from L2 into a contenthash. Limo and/or any contenthash relayer that supports CCIP-Read can simply add support for Data URL contenthash specifications and ENS instantly gains an affordable Ethereum-aligned dweb solution. URL (using a 30X redirect) gives ENS users an effortless way to link to existing web2 content using their web3 identity.
TBH, I really dislike the contenthash coding. It incurs a large client-side burden to reduce on-chain data. However in practice, most contenthash’s are larger than 32 bytes, so the literal decoded URL form would have similar storage cost without any library requirement and complete generality (with the exception of data URLs paying base64 overhead and possible URL size limits for some clients.)
3 Likes
I understand data:uri format isn’t under multicodec specs, our rational was to simplify hex(data:uri…) as namespace prefix. We already closed this PR for alternative cidv1 raw/json codec based generators, and there’s no content/mine types support yet in cidv1.
& next alternative is to wait… proll’y cidV2? ![]()
- Mimetypes as codes · Issue #4 · multiformats/multicodec · GitHub
- feat: assign codes for MIME types by Stebalien · Pull Request #159 · multiformats/multicodec · GitHub
We can generate “dynamic” contenthash using on-chain data and multicodec/CIDv1.
eg. ENS resolver for <0xaddress>.dai.notapi.eth wildcard subdomain can read taht address’s dai balance and return that as raw/JSON encoded as IPFS contenthash.
Js >
let data = { block: "123456", timestamp:12345678, balance: 123414......, approved:"0x0" }
const cid = CID.create(1, json.code, await identity.digest(json.encode(data)))
eg, dynamic contenthash can be generated on-chain using cidv1 raw data & dag-cbor links…
0xe301017100d501a564626c6f67d82a582500017012206dc0963510e2c7ae8be606feaa01f9e8982bc5abad7ec95f4e3e9a26b554afaa6468746d6cd82a581900015500143c68313e48656c6c6f20576f726c643c2f68313e646a736f6ed82a570001800400117b2268656c6c6f223a22776f726c64227d6773637269707473a16a7465782d7376672e6a73d82a582500017012206ca59222e19c2534b76a086b813a84ca963d0cb85927c2097b2269dc1fe661fd6a696e6465782e68746d6cd82a581900015500143c68313e48656c6c6f20576f726c643c2f68313e
JSON codec is supported in multiformats,
but for everything else we’ve to use raw/plaintextv2 from multiformats/multicodec.
it works ok when paired with default ipfs gateways… only down side, raw data is right there but dapps/ipfs gateways have to request ipfs node/gateways to resolve content-type, if that raw data is html fragment or random file starting with <… that’s the problem we were trying to solve with plain hex(data:uri) in contenthash…
1 Like
Why was this field not called multicodec? What is bugging me here is that contenthash refers to a very specific thing, and not all multicodecs are content hashes IIUC.
1 Like
2 Likes
reposting my github reply here for future/context…
We did our homework before sending draft over ENS forum to make an exception for hex(“data:”) prefix for reasons below…
a) mime/content type support in cidv1 is pending for loong time (?wen cidv2?)
feat: assign codes for MIME types by Stebalien · Pull Request #159 · multiformats/multicodec · GitHub
Mimetypes as codes · Issue #4 · multiformats/multicodec · GitHub
b) ENS already supports string(data:uri) format in avatar records,
so contenthash with plaintext bytes(data:uri) as hex(“data:”) namespace is full RFC2397 & it won’t collide with cidv1 namespaces.
if(contenthash.startsWith("e301")){
//ipfs
} else if(contenthash.startsWith("e501")){
//ipns
}
// else... other contenthash namespaces...
else if(contenthash.startsWith(hex("data:"))){
//datauri
}
ENS is not ready for such changes with new ENSIP specs, all contenthash MUST follow namespace+CIDv1 format.
&& we’re back to square one, using raw data in cidv1 with IPFS namespace.
our current working specs for on-chain raw IPFS+CIDv1 generator without content/mime types…
import { encode, decode } from "@ensdomains/content-hash";
import { CID } from 'multiformats/cid'
import { identity } from 'multiformats/hashes/identity'
//import * as cbor from '@ipld/dag-cbor'
import * as json from 'multiformats/codecs/json'
import * as raw from 'multiformats/codecs/raw'
const utf8 = new TextEncoder()
const json_data = {"hello":"world"}
const json_cid = CID.create(1, json.code, identity.digest(json.encode(json_data)))
-
JSON/cidv1 >> 01800400117b2268656c6c6f223a22776f726c64227d
https://ipfs.io/ipfs/bagaaiaarpmrgqzlmnrxseorco5xxe3deej6q -
ENS contenthash with IPFS namespace : 0xe30101800400117b2268656c6c6f223a22776f726c64227d
eth.limo tests :
https://e3010180040011.7b2268656c6c6f223a22776f726c64227d.ipfs2.eth.limo
https://bagaaiaarpmrgqzlmnrxseorco5xxe3deej6q.ipfs2.eth.limo/
const html_data = "<h1>Hello World</h1>";
const html_cid = CID.create(1, raw.code, identity.digest(utf8.encode(html_data)))
-
HTML/cidv1 >> 015500143c68313e48656c6c6f20576f726c643c2f68313e
https://ipfs.io/ipfs/bafkqafb4nayt4sdfnrwg6icxn5zgyzb4f5udcpq -
ENS contenthash with IPFS namespace : 0xe301015500143c68313e48656c6c6f20576f726c643c2f68313e
eth.limo tests :
https://e30101550014.3c68313e48656c6c6f20576f726c643c2f68313e.ipfs2.eth.limo/
https://bafkqafb4nayt4sdfnrwg6icxn5zgyzb4f5udcpq.ipfs2.eth.limo/
This all works ok using json/raw data… only down side, there’s no content/type in CIDv1 so we’ve to parse/guess magic bytes in raw data on client side OR request ipfs gateways to resolve that.
we can even use dag-cbor to link multiple files/ipfs cids… but on public ipfs gateways there’s no index file and ipfs __redirect supported. we’ve to happily decode that on our “smart” clients for now.
const blog = CID.parse("bafybeidnycldkehcy6xixzqg72vad6pitav4lk5np3ev6tr6titlkvfpvi")
let link = { json: json_cid, "/": html_cid, "index.html": html_cid, blog: blog }
let cbor_link = CID.create(1, cbor.code, identity.digest(cbor.encode(link)))
Back to @adraffy’s f3 namespace, I’d suggest this format…
const data_uri = "data:text/html,<html>hello</html>";
const data_cid = CID.create(1, raw.code, identity.digest(utf8.encode(data_uri)))
- RAW CIDv1 with full data uri string : 01550021646174613a746578742f68746d6c2c3c68746d6c3e68656c6c6f3c2f68746d6c3e
01 - 55 - 00 - 21 - 646174613a746578742f68746d6c2c3c68746d6c3e68656c6c6f3c2f68746d6c3e
v1 - codec/raw - hash/none - varint.encode(datauri.length) - utf8 datauri
https://ipfs.io/ipfs/bafkqailemf2gcotumv4hil3iorwwylb4nb2g23b6nbswy3dphqxwq5dnnq7a
ENS contenthash with data-uri “f3” namespace :
0xf30101550021646174613a746578742f68746d6c2c3c68746d6c3e68656c6c6f3c2f68746d6c3e
2 Likes
We could use URI: [ipfs + CID w/identity "url"] or Data URL: [ipfs + CID w/JSON "{mime, data}"] but I think it’s better to have these protoCodes at top-level so the use-case is clear. For example, a future contenthash could potentially be a reverse-proxy, but that is also an url.
Nick suggested above that these should be separate codecs:
I do like the various dag concepts (esp. merkle dag using transaction hashes) for describing some kind of indirect linked directory or file but I think that should be another top level protoCode.
I interpret the ENSIP-7 definition <protoCode uvarint><value []byte> such that value could be anything as long as we reserve protoCode as a valid multicodec. And the use-case of protoCode is that it describes how value is interpreted to satisfy the requirement of a contenthash, which is either displaying a website (the content) or describing what it will display (the hash in human-readable form: a URL).
I want this ENSIP to proceed as the Data URL contenthash seems especially useful for offchain and EVM gateway-based applications. Single-file inline content is still limiting (1 file, gas cost, …) but useful.
A 3rd dag-like option for directories would be awesome, but requires a lot of infrastructure and apps to manage that content, whereas URI and Data URL are dead simple and can be used by anyone.
Lastly, I still like the 4th option that’s equivalent to “use my text("url")” (eg. just <protoCode> and nothing else) but maybe this could be a fallback instead?
I was focused on data:uri only.. URL is totally different topics, I’ll do a followup on that soon..
I think IPLD Namespace is best for data:uri. & all this concept initially was for IPLD with dag-cbors to store ENS records and ccip callback signatures off-chain.
so I’d suggest changing 0xf3 from namespace to “ipld” multicodec,
& then add IPLD NS support in ENS contenthash.
we can use that for all types of ipld data including raw data:uri under same NS.
| namespace | multicodec | multihash | length | data |
|---|---|---|---|---|
| 0xe2 | 0xf3 | 0x00 | length | data:uri |
| IPLD-NS | codec/data-uri | raw/identity | length | data:uri |
0xe20101f3010021646174613a746578742f68746d6c2c3c68746d6c3e68656c6c6f3c2f68746d6c3e
I’m not sure if we can break apart length+ content type before raw data,
or * in other words, IDK if there’s another cidv1.create(…) function with extra input for that len+content/type data+extra encoding info in data uri..
IPLD-NS | codec/data-uri | contenttype | data.length | raw data without data:uri prefix
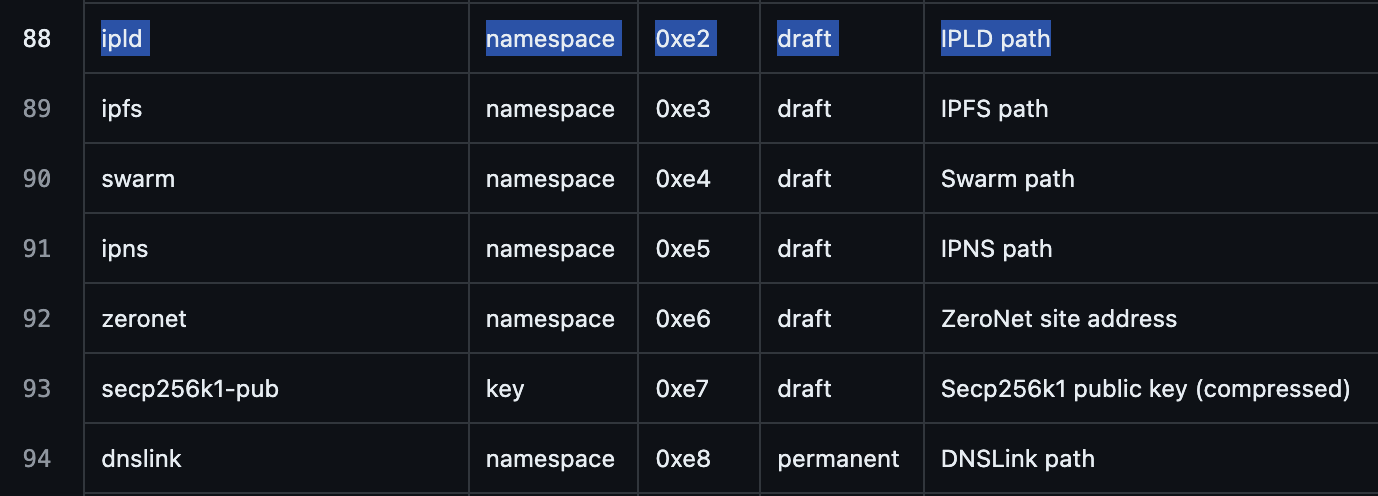
So at total we’ve 3 options for this..
a) skip CIDv1 to use hex(data:uri…)
b) IPFS-NS with json/raw. we don’t get content/type info, clients/gateways can take a shot at that or use IPFS gatteways as it’s ll backwards compatible with IPFS.
c) IPLD-NS with 0xf3 multicodec for data:uri..
We’ve to write encoder/decoder for this new multicodec/data-uri for IPFS/ENS gateways to resolve that content/type+raw data:uri properly. &? do we also need new ENSIP for this? or as fully multiformat/multicodec compatible ns+cidv1 format we get free pass under old ENSIP?
2 Likes
I’m concerned about overloading the top-level IPFS codec with other subtypes that aren’t related to IPFS. This is related to my question from earlier:
For example, why wasn’t IPNS just IPFS w/ libp2p-key?
Conceptually, I think of <protoCode><bytes[]> as protocol://human-readable
1 Like
CIDs are self-describing content-addressed identifier, it’s NOT IPFS only multiformats so we’re not overloading multiformats.csv, it’s supposed to have all types of multiformats, addrs and codecs used by other crypto projects ** (there’s long list of dag-git, btc, eth or any alt chain/tx formats in multiformats, && we’re nowhere near to building our own dag/ipld schemas for ENS to store verifiable offchain records & metadata)…
namespace | version | codec | multihash | hash.length | hash
- if hashing algo is none/id=0, hash.length = raw data length & hash = raw data
It is… That’s how it’s represented in CIDv1 hash (base16/32/36…) without namespace, ENS/contenthash is using extra namespace/prefix so we don’t have to add full multiformat/codecs.csv support in contenthash resolver codes to parse whole CID to find if it’s IPFS/IPNS or Arweave or Swarm…
__
IPFS is a “type of” IPLD with immutable FS
IPNS is mutable DHT KV mapping (pubkey => record),record data includes version n, validity, ttl & IPFS hash… & technically ENS is IPNS too > ipns://vitalik.eth but we don’t have that _dnslink record support. ![]()
IPLD is core CID space open for developers, we can pack our data in D/App specific schema/codecs…
3 Likes
Can we fork Ethscriptions protocol and call upon Input Call data # ?
ie for avatars, html, text records which are pre inscribed and then the ens records knows the tx # to pull in the relevant data to the ens front end.
I am more than certain this is possible and would no doubt incur less gas costs as there is no smart contract needed in order to first create the ethscription data uri.
I apologise if my terminology isn’t 100%. Would be happy to showcase this in more detail with some mock up ideas for working examples.
1 Like
0x2a568d9649899cf903ffad2d3e2dad98792ccfaffb18c744740eb56459adbd6e
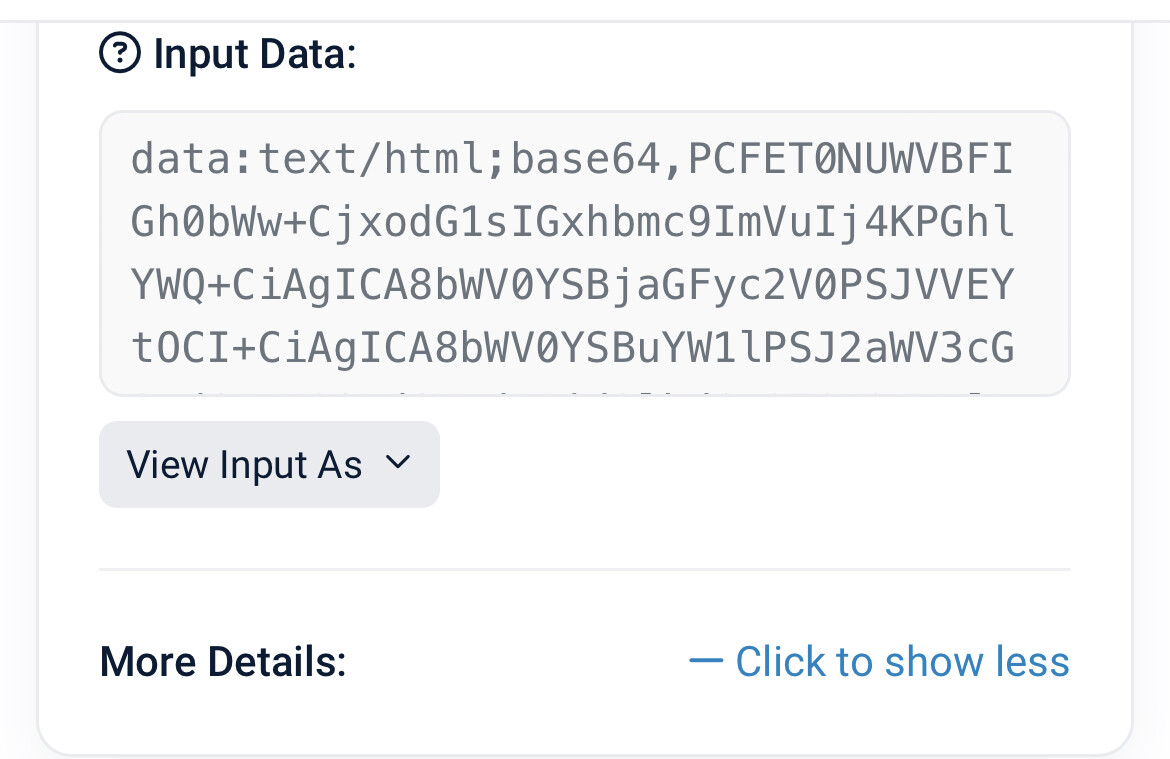
Which when called up and decoded back into html, it runs this as an interactive 3D emoji universe…

1 Like
Ethscriptions definitely would work in contenthash, but I think it’s a separate protoCode. Unruggable has sketched some ideas for a contenthash format based on inscriptions, where you’d be able to describe a file or directory, link to existing inscriptions, and make partial edits (instead of re-inscribing the entire directory.) There also needs to be a way to chunk a blob across multiple inscriptions. There’s been some discussion whether this format should be able to pull data from multiple chains.
IMO, although Data URL could just contain a pointer to another resource (eg. a Data URL of JSON file that contains an HTTP URL), the typical use-case of a Data URL is to fully-encapsulate the data. The main focus of Data URL in contenthash would be to store the data entirely on-chain–and then put that data on L2 and fetch it through EVMGateway.
1 Like
VWA is all reinventing CAR (v1/v2) wheels. ![]()
CAR = verifiable Content-Addressed aRchive
eg, reading vitalik.eth’s ipfs as car/dag-json format
https://vitalik-eth.ipns.dweb.link/?format=car
downloads partial or full content archive of vitalik.eth
{
"Data": {
"/": {
"bytes": "CAE"
}
},
"Links": [
{
"Hash": {
"/": "QmXp4WFJ4oCeX9YDWcLpACdyL4H4HF26tawiyymBm9BGP6"
},
"Name": "categories",
"Tsize": 155848
},
{
"Hash": {
"/": "QmNTP17BS7AEHn4TuiyKYtKq1StCMxxXRSt4gpiTdyuHRB"
},
"Name": "css",
"Tsize": 368668
},
{
"Hash": {
"/": "QmYCmvfoV92T2cG8NhSi2qTB4Y7mvWM6viqbR14UXb7Dy2"
},
"Name": "feed.xml",
"Tsize": 38732
},
{
"Hash": {
"/": "QmbbNaE7emJjPbGx5hB9CigkdWeugiDPXDWHB4QjgJm8p9"
},
"Name": "general",
"Tsize": 3982170
},
{
"Hash": {
"/": "QmaKzjz9eKd9titaUy7Wq6Ue9R9tbXJZdHSY9W44Q3NvBv"
},
"Name": "images",
"Tsize": 72465865
},
{
"Hash": {
"/": "QmNYx2nKCaYtMyxKzySXR5k58nRxdGnr2nZmtPBJuDDQY2"
},
"Name": "index.html",
"Tsize": 31340
},
{
"Hash": {
"/": "QmRyoGE1B1NvhqKX6Vjs7dH7skDd85hgoKoSDFYMhVSn4D"
},
"Name": "scripts",
"Tsize": 1745105
}
]
}
2 Likes