In the past week, thousands of “emoji-only” domains have been registered on ENS, and the second-hand market for valuable/unique/rare “emoji-only” domains is quickly growing. Because emoji is complicated, unicode is complicated, ENS is complicated, etc, several edge cases have emerged which may warrant additional consideration from the ENS development team. This thread describes one such edge case.
UTS-46 non-compliant emoji
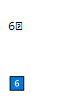
Because UTS-51 compliant emoji characters were never designed to be compatible with the UTS-46 normalization procedures ENS has adopted, there are some “official” emoji which include unicode characters ignored or disallowed by UTS-46. When these emoji are input into app.ens.domains, UTS-46 normalization strips the problem characters. This process transforms the emoji from a “fully-qualified” emoji into a “minimally-qualified” or “unqualified” emoji (see http://www.unicode.org/reports/tr51/#def_fully_qualified_emoji for complete definitions of these terms, and https://unicode.org/Public/emoji/14.0/emoji-test.txt for a list of each classification). Depending on the user’s platform and system fonts, this normalization may or may not be visually apparent to the user. If the normalized domain is registered, the “minimally-qualified” or “unqualified” representation is stored within the ENS registrar, and subsequent resolution will also return the “minimally-qualified” or “unqualified” emoji.
This screenshot was taken on Chrome/Mac, where “minimally-qualified” emoji are supported:
This screenshot was taken on Firefox/Linux, where “minimally-qualified” emoji are not supported:
And this was taken after Metamask resolution on Chrome/Mac:
What does the ENS team think of this? Specifically, should ENS continue to store and resolve “minimally-qualified” or “unqualified” emoji in its registrar? Should these type of emoji be encouraged or discouraged for use within ENS domains? Would ENS ever consider emoji-specific exceptions to UTS-46 normalization? If the Unicode Consortium ever brought UTS-51 into full compliance with UTS-46, would ENS adopt the new mapping tables?
I don’t think we should compromise the integrity of ENS to accommodate this narrow “emoji” use-case, but I also think “emoji” ENS domains are an interesting, exciting, and promising way with which the ENS platform can grow and expand to new users. I’m curious to hear other opinions on this.

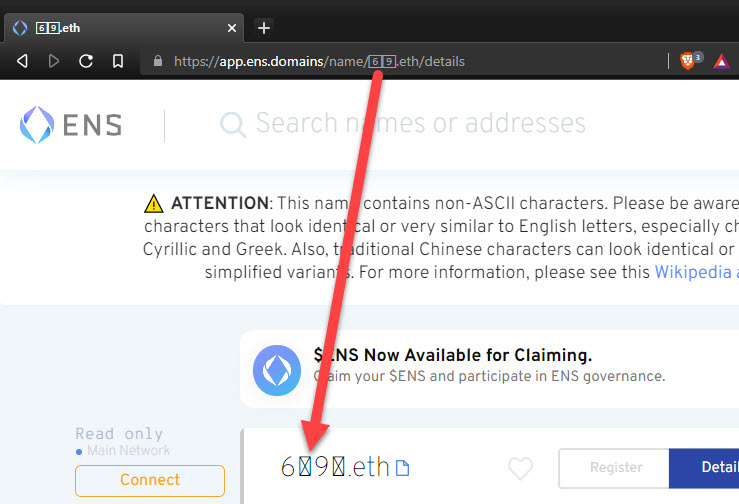
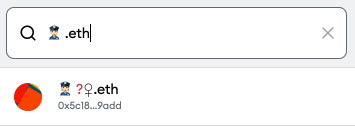
 .eth and registered via the ENS manager app, you will actually register 6⃣9⃣.eth. And then if you enter
.eth and registered via the ENS manager app, you will actually register 6⃣9⃣.eth. And then if you enter