Thoughts on disallowing skin tone and hair modifiers as singular emoji?
Stats: 6701 names with modifiers (98% valid), 18 pure modifier names, 109 names contain a singular modifiers.
There is ambiguity around trailing skin-color with ZWJ sequences that contain modifiable characters.
-
There exist dedicated ZWJ sequences with skin-color styling:
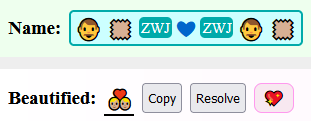
-
The following ZWJ sequence is followed by a skin-color modifier, however it presents like a single emoji, with one golden human and one skin-colored human.
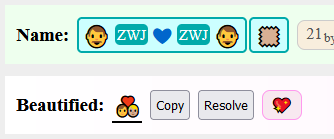
According to the spec, this should present like:

Disallowing singular modifiers would prevent this problem.
A separate decision would be to whitelist these mixed modifier ZWJ sequences (I say no.)
