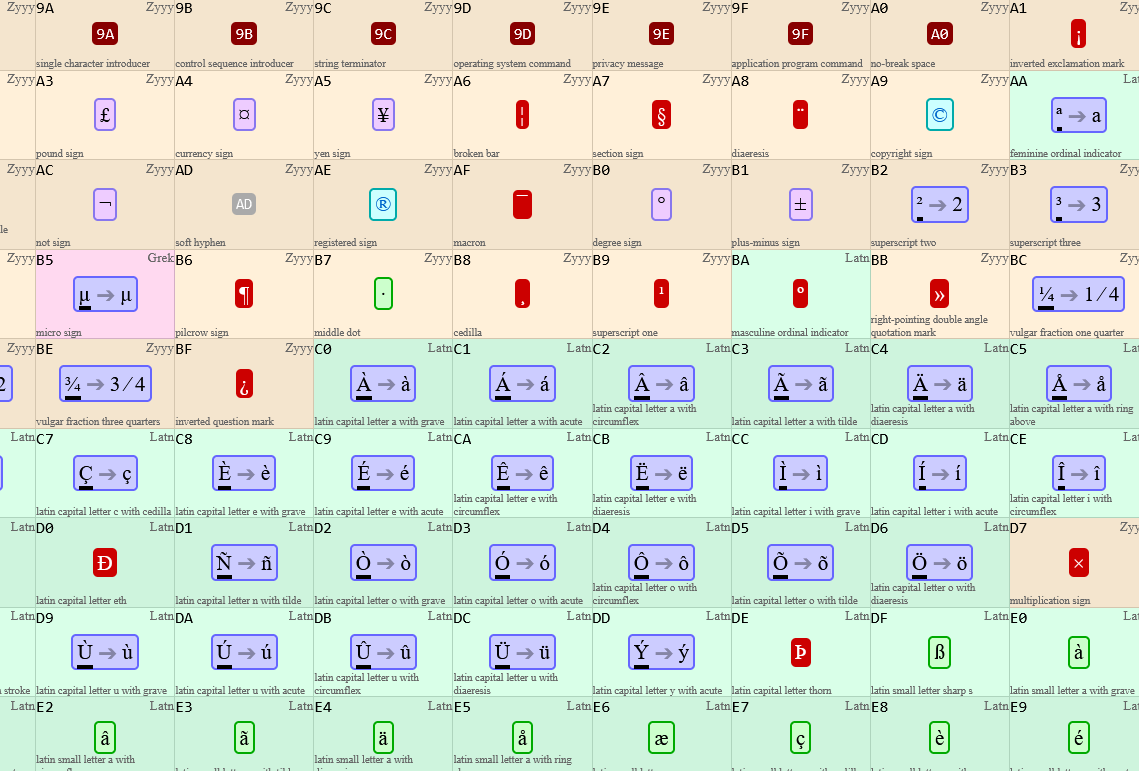
So to clarify, would -0-.eth be invalid, but -00-.eth would be?
I forgot about the leading underscores, is that still just leading?
After thinking about this for some weeks, I really would think everything through with the mappings/groupings. I can think of weird things, like in Dutch ij is one letter, and their keyboard has it as one letter, but everyone Dutch doesn’t want a Dutch keyboard because everyone speaks English. I remember learning Dutch for a year after I lost my phone in Amsterdam in a taxi. I replaced it with the same one, except the Windows CE version it was in was locked to Dutch language. It was a lot of money, so I just learned the Dutch UI instead of buying another phone. My Dutch friends laughed a lot. Microsoft didn’t get that localizing for Dutch meant putting things in English.
The context of that long story matters because even in that localization there wasn’t ij as a letter in the primary keyboard, it was an alternate still, so I always just typed the two letters. This kind of scenario where you can spell things both ways can be infuriating when mapping languages to specific keysets, or making word lists.
I write in Spanish often (poorly), but I never use accents or the ñ because I have an English keyboard. In fact, the English speaking city where I crew up had a street name in Spanish with an ñ, and 30 years on, now it’s replaced with just an n, and everyone says the street name wrong. Kind of like how everyone says Crimea wrong today in English (Hint: it never rhymed with crime before the 2000s). A simple gap in history, and new history was made. I hope the same thing doesn’t happen to more obscure languages just because someone not familiar with the language makes a booboo. I’m not going to take any political stance here, but I do think perception has shifted based on the pronouncing of Crimea, and writing things as Karabakh instead of Artsakh. Almost nobody means harm doing it, but yet ignorance got in there and massaged history for the eyes of outsiders.
Æ and Œ are both valid letters in English. Just because English changed to omit these letters most of the time does not make them less valid. It’s similar to church Russian or old Russian. Ij in Dutch has kind of one the way of Æ and Œ, but in our lifetime. It’s why it was already relegated on the keyboard circa 2006. Should Œ map to oe? Are they the same?
I know how to pronounce them, but I have no idea how to even argue for what to do if there were a mapping of just English letters. Who decides the English alphabet? Is it all of the English words that ever existed? Is it just what is currently taught in schools? What about dialects of English that have weird digraphs?
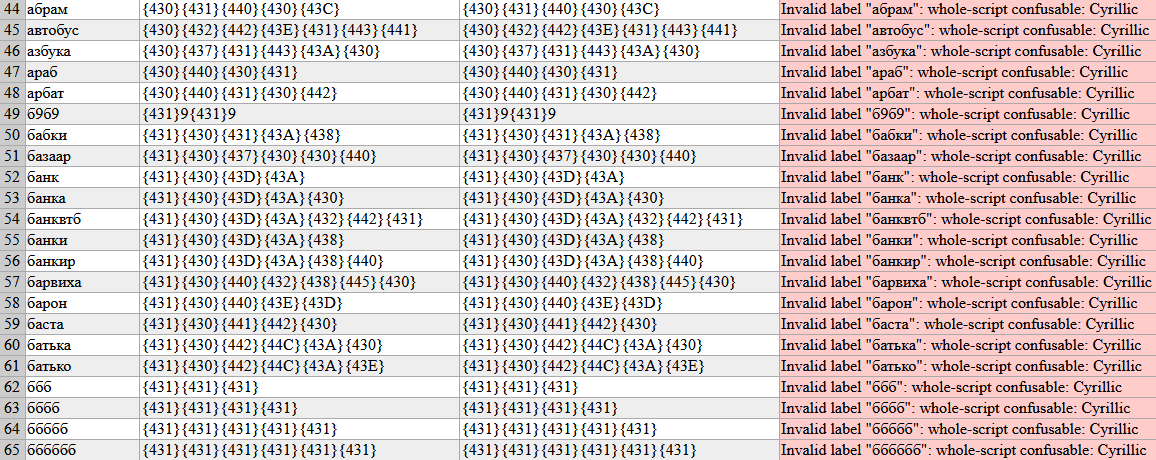
 and
and  to change (they’ll be uncolored
to change (they’ll be uncolored 
 .
.


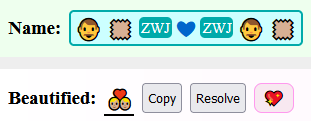
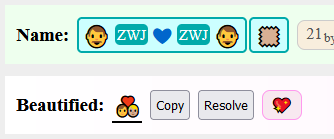






 ) enabled as they function slightly differently and don’t seem to collapse/merge into existing sequences (as it requires an additional ZWJ).
) enabled as they function slightly differently and don’t seem to collapse/merge into existing sequences (as it requires an additional ZWJ).