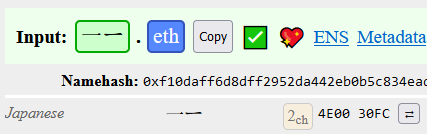
Single-script confusables have the same problem as script ordering does: since we have a global namespace, the only way to resolve these situations is to say character A > character B (ie. order them) and disallow the alternatives.
These are the valid single-script confusables for Arabic
// Single: [30B]
0x64B, // (◌ً) ARABIC FATHATAN
0x8F0, // (◌ࣰ) ARABIC OPEN FATHATAN
// Single: [307]
0x6EC, // (◌۬) ARABIC ROUNDED HIGH STOP WITH FILLED CENTRE
0x8EA, // (◌࣪) ARABIC TONE ONE DOT ABOVE
// Single: [350]
0x8FF, // (◌ࣿ) ARABIC MARK SIDEWAYS NOON GHUNNA
0x8F8, // (◌ࣸ) ARABIC RIGHT ARROWHEAD ABOVE
// Single: [64C]
0x8F1, // (◌ࣱ) ARABIC OPEN DAMMATAN
0x8E8, // (◌ࣨ) ARABIC CURLY DAMMATAN
0x8E5, // (◌ࣥ) ARABIC CURLY DAMMA
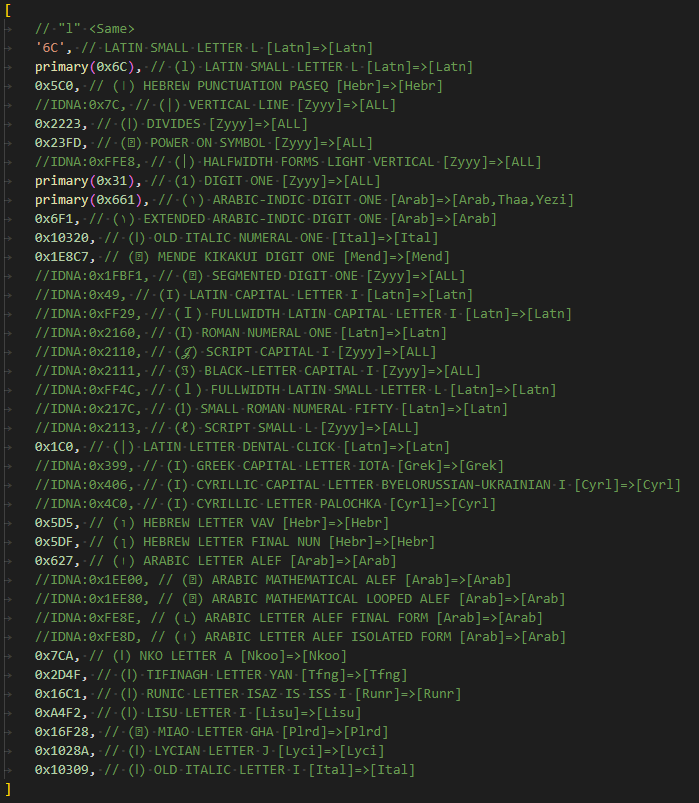
// Single: [6C]
0x661, // (١) ARABIC-INDIC DIGIT ONE
0x627, // (ا) ARABIC LETTER ALEF
// Single: [6F]
0x665, // (٥) ARABIC-INDIC DIGIT FIVE
0x6F5, // (۵) EXTENDED ARABIC-INDIC DIGIT FIVE
0x647, // (ه) ARABIC LETTER HEH
0x6BE, // (ھ) ARABIC LETTER HEH DOACHASHMEE
0x6C1, // (ہ) ARABIC LETTER HEH GOAL
0x6D5, // (ە) ARABIC LETTER AE
// Single: [754]
0x8A9, // (ࢩ) ARABIC LETTER YEH WITH TWO DOTS BELOW AND DOT ABOVE
0x767, // (ݧ) ARABIC LETTER NOON WITH TWO DOTS BELOW
// Single: [62D 654]
0x681, // (ځ) ARABIC LETTER HAH WITH HAMZA ABOVE
0x772, // (ݲ) ARABIC LETTER HAH WITH SMALL ARABIC LETTER TAH ABOVE
// Single: [6A1]
0x8BB, // (ࢻ) ARABIC LETTER AFRICAN FEH
0x8BC, // (ࢼ) ARABIC LETTER AFRICAN QAF
// Single: [6A1 6DB]
0x6A4, // (ڤ) ARABIC LETTER VEH
0x6A8, // (ڨ) ARABIC LETTER QAF WITH THREE DOTS ABOVE
// Single: [643]
0x6A9, // (ک) ARABIC LETTER KEHEH
0x6AA, // (ڪ) ARABIC LETTER SWASH KAF
// Single: [643 6DB]
0x6AD, // (ڭ) ARABIC LETTER NG
0x763, // (ݣ) ARABIC LETTER KEHEH WITH THREE DOTS ABOVE
// Single: [649]
0x6BA, // (ں) ARABIC LETTER NOON GHUNNA
0x8BD, // (ࢽ) ARABIC LETTER AFRICAN NOON
0x64A, // (ي) ARABIC LETTER YEH
0x6CC, // (ی) ARABIC LETTER FARSI YEH
0x6D2, // (ے) ARABIC LETTER YEH BARREE
// Single: [649 615]
0x679, // (ٹ) ARABIC LETTER TTEH
0x6BB, // (ڻ) ARABIC LETTER RNOON
// Single: [649 6DB]
0x67E, // (پ) ARABIC LETTER PEH
0x62B, // (ث) ARABIC LETTER THEH
0x6BD, // (ڽ) ARABIC LETTER NOON WITH THREE DOTS ABOVE
0x6D1, // (ۑ) ARABIC LETTER YEH WITH THREE DOTS BELOW
0x63F, // (ؿ) ARABIC LETTER FARSI YEH WITH THREE DOTS ABOVE
// Single: [649 306]
0x756, // (ݖ) ARABIC LETTER BEH WITH SMALL V
0x6CE, // (ێ) ARABIC LETTER YEH WITH SMALL V
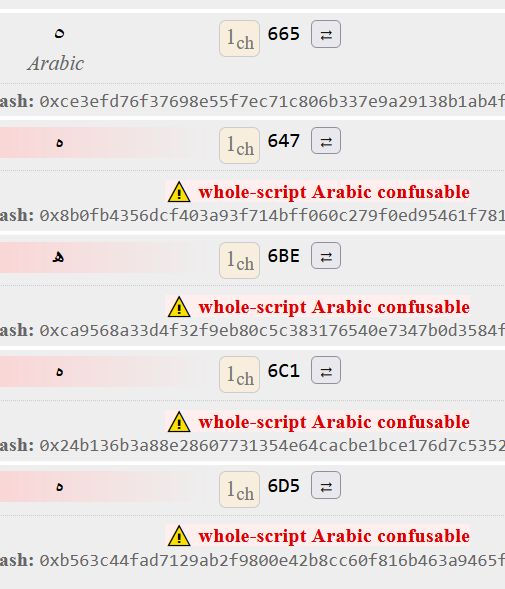
For an example, here are 6F confusables (which are the symbols that looks like Latin “o”) for Arabic (from the above spoiler):
0x665, // (٥) ARABIC-INDIC DIGIT FIVE
0x6F5, // (۵) EXTENDED ARABIC-INDIC DIGIT FIVE
0x647, // (ه) ARABIC LETTER HEH
0x6BE, // (ھ) ARABIC LETTER HEH DOACHASHMEE
0x6C1, // (ہ) ARABIC LETTER HEH GOAL
0x6D5, // (ە) ARABIC LETTER AE
We already have 6F5 mapped to 665. Of the remaining symbols, which one is preferred or which ones aren’t actually confusing?
I would say 665 is visually different from 6BE. 647/6C1/6D5 look the same but are visually distinct from the 655 and 6BE. Only 1 of those 3 would be allowed but I don’t know which one.
-
647 has 753 registrations
-
6C1 has 12
-
6D5 has 1
This makes me think that 6C1 and 6D5 should be disallowed.
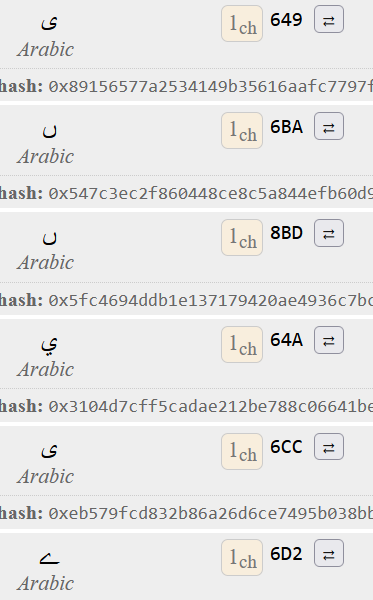
For your example, these are Arabic confusables for 649 (which is also Arabic)
0x649, // (ى) ARABIC LETTER ALEF MAKSURA <= Confusable Primary
0x6BA, // (ں) ARABIC LETTER NOON GHUNNA
0x8BD, // (ࢽ) ARABIC LETTER AFRICAN NOON
0x64A, // (ي) ARABIC LETTER YEH
0x6CC, // (ی) ARABIC LETTER FARSI YEH
0x6D2, // (ے) ARABIC LETTER YEH BARREE
-
649 has 108 registrations
-
6BA has 0
-
8BD has 0
-
64A has 3171
-
6CC has 122
-
6D2 has 2
This looks like 3 separate characters to me:
-
649, 64A, 6CC (64A has dots and 649/6CC do not)
6BA, 8BD6D2
From this, I would disallow: 649 and 6CC based on registrations. I don’t know how to choose between 6BA and 8BD (both 0 regs).
If those dots make 64A distinct, I would keep 649.
As a potential solution: for each script, I could compute a report of the single-script confusable groups along with their registration counts. I would need users of those scripts to discern if any of those groups should be broken up further, and for each remaining group with 2+ characters, which is the preferred character. The end result is simple: non-primary single-script confusables must be disallowed.
Just to clarify: imagine the name “XY” where X and Y are single-script confusable. If you simply enforce both X and Y can’t be used together, then “XX” and “YY” would be valid but since confusable means X looks like Y, that also means “XX” looks like “YY”, thus only one must be allowed (unless they weren’t confusable in the first place.)
 vs
vs  ), -nearly identical (
), -nearly identical ( vs
vs  ), or mask-identical (
), or mask-identical ( vs
vs  ) on various platforms. Given an emoji, it would nice to know how closely you should inspect it.
) on various platforms. Given an emoji, it would nice to know how closely you should inspect it.