For now, I’ll have a global setting for any script with more than 1 undecided confusable, and I’ll default to allow. However, I do think many these characters are confusable and should be reduced to one.
Previously, I ran into two problems while trying to finalize my latest changes in words. I had a problem sharing characters between multiple scripts and I was confusing on names of the form AB where A was A-C confusable and B-D confusable but C-D isn’t confusable—essentially it was confusing against a name that wasn’t possible. I also had the script logic setup an inefficient way which required all of the esoteric stuff to be tested first.
I discovered these issues while updating the ENSIP document and making some small adjustments based on some input I’ve been getting from other ENS users.
In fixing this issue, I think I greatly simplified the process.
First, there’s the description of the different types of names we want to allow. At the moment, these are script-centric (I’ve been calling them ScriptGroups), but they could be more general. Here are two examples:
{name: 'Latin', test: ['Latn'], rest: ['Zyyy', 'Zinh'], cm: -1, extra: explode_cp('π')}
{name: 'Japanese', test: ['Kana', 'Hira'], rest: ['Hani', 'Zyyy'], cm: -1, romanize: true}
The way it’s defined is unrelated to what it actually is—it’s simply a set of characters and some rules for which characters can have combining marks.
{name: 'Latin', cps: [61, 62, ...], cm: ['â', ...]}
{name: 'Japanese', cps: [...], cm: [...]}
Second, there’s the IDNA-like part, where you take a string, parse out emoji, remove ignored characters from remaining sections, apply mappings, and then NFC those segments. This produces a simplified version of ens_tokenize() which only has 2 token types:
[ Emoji("💩"), Emoji("💩"), NFCString("a"), Emoji("💩"), NFCString("bc") ]
You actually don’t need to know if the characters are valid at this point. However, you can precompute a union from the characters in each ScriptGroup (and their decomposed parts) to fail early. You can also precompute non-overlapping sets, for which only a unique group can match. From the original group definitions, the characters can also be split into primary/secondary. For example, “a” is primary to Latin and “1” is secondary to Latin (since it’s primary to Common.)
This makes the matching logic very simple:
- Given the list of simple tokens, just look at the textual ones.
- For each character, see if there is a unique group.
- If there is more than one unique group, error you have an illegal mixture.
- If you didn’t have a unique group, find all the groups that contain any primary character in the label.
- If there’s no groups, error you have some weird name that matches no groups.
- At this point, you have at least one group.
- For each group, check if every character is valid according to that group and apply the combining mark rules. The first group that matches will work. If no group matches, throw the first error that occurred.
Note: there are strings that are made entirely of valid characters but match no groups. There are also strings that match multiple groups (which also may have different combining mark rules.)
With this setup, the order of the groups only matters for when you have a name that matches multiple groups (and the choice really doesn’t matter). For example, any digit that’s shared between multiple scripts, might fail on a restricted group but pass on normal group. I’ve set the order of the groups to match the distribution of registrations for efficiency. It’s also easy to just extract 1 group, like Latin, and ignore everything else, which would make a very tiny library.
For marks, I support a few modes: either you can explicitly whitelist compound sequences like, “e+◌́+◌̂” (which I’m doing for Latin/Greek/Cyrillic and a few others) or you can specify how many adjacent marks are allowed (when decomposed). The set of available marks is also adjustable per ScriptGroup (most marks are in the Zinh script because they’re shared between multiple scripts, but some script extensions give scripts all their own marks.) For example, I can bump Arabic to 2 and Common to 0, while leaving restricted groups at 1.
There’s also 2 Unicode script adjustments: There’s script extensions, which change a singular (Char → script) map to a (Char → Set<script>). For example, there are some characters used in exactly N scripts, but not in any others (unlike Zinh which is allowed in all). There’s also augmented scripts, which permits separate scripts to mix, like Kana+Hani or Hira+Latin. Lastly, there’s edits we might want to make, like letting a restricted script access it’s currency symbol or allowing a scripted character (ether symbol is Greek) to be used universally.
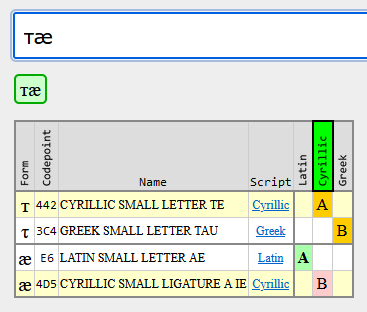
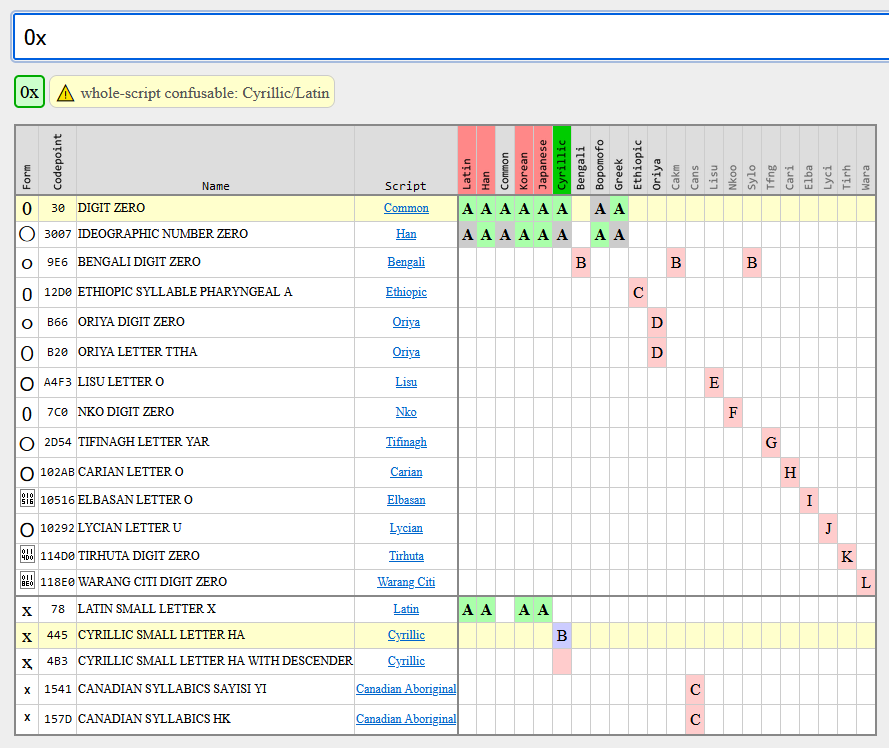
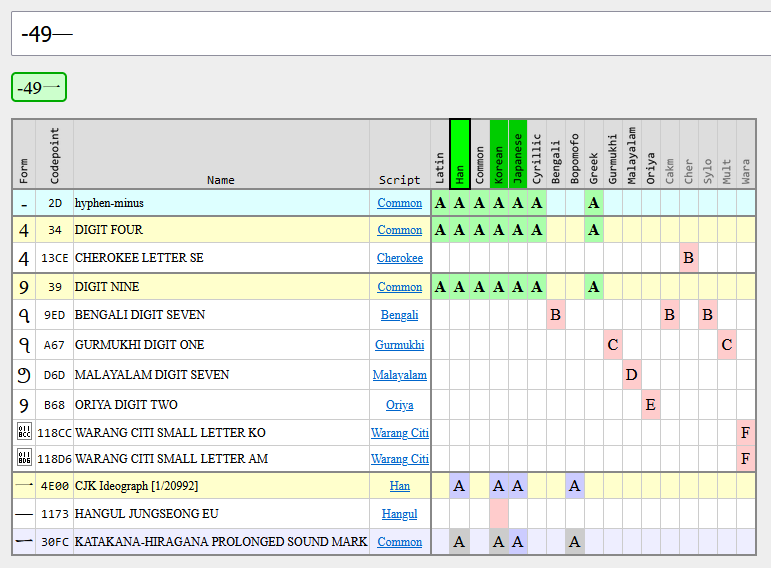
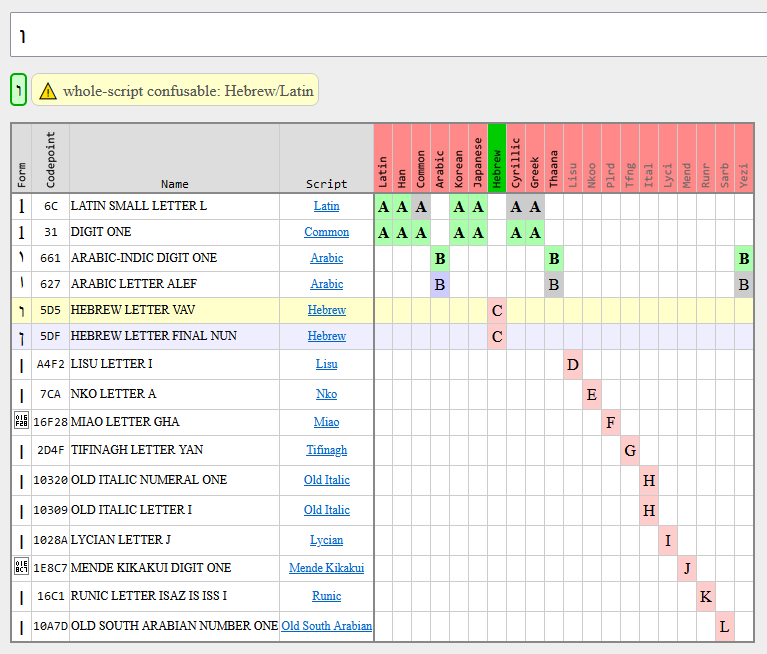
And lastly there’s confusables, which are a set of different contiguous sequences which compose visually-indistinguishable. Unicode provides only a 1-character to a N-character map, eg. the single character "ɨ" looks like "i+◌̵" (which is 2). Confusables between different groups is one problem (whole-script confusable). Confusables of the same group are another (single-script confusable.) Mixed-script confusables are replaced by the ScriptGroup logic, which allows you to construct a Japanese name with Kana+Hira+Hani+Zyyy+Latn+Emoji but not Latn+Grek.
This makes the process simple: just need to generate the correct ScriptGroups according to all these constraints, which allow the simple matching logic to work 100%.
I think I’ve solved the issue. I appreciate the patience.