I had my first bug report in ens-normalize for a misnamed variable in the combining mark counting code. Fortunately, it impacts no registered names, but it indicated a missing test case: a string with both decomposable characters and excess combining marks near the end of the string. It was found by Carbon225 while developing of a Python normalization port.
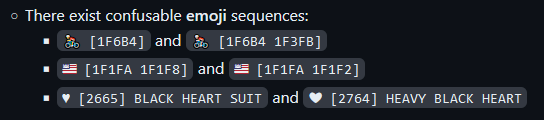
Related: there are only a few names that fail due to excess combining marks (most true abuses fail earlier for different reasons, like illegal use or invalid mixtures). If anyone with experience with these remaining examples could comment about the validity of these names, it would be greatly appreciated.
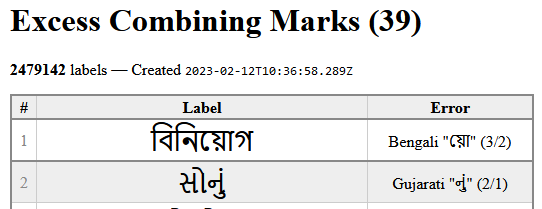
The notation used below is that the name matches the group Bengali but a character was found that is followed by 3 CM, where the maximum allowable was 2 (eg. 3/2). I’m contemplating changing the CM limit to 3 for all non-CM-whitelisted groups. I’m currently using a value of 1 or 2 (see: cm:#).. Edit: the Unicode recommendation is max of 4 NSM.
I had a request to enable a different check character, likely due to the popularity of the Checks NFT. Upon further inspection, it does land in an unfortunate grey area.
2714 (✔︎✔️) heavy check mark — 2713 (✓) check mark

My convention for deciding amongst characters of different weights (very thin, thin, regular, medium, heavy, very heavy, etc.) was to choose the heavy variant if available. For checks, the heavy variant is also the emoji character.
Because normalized emoji have their FE0F stripped and check is default text-presentation (Emoji_Presentation=false), a normalized check emoji looks like a bold textual check. I made a simple demo which shows a few heavy variants with emoji forms and their corresponding most similar textual character (“alt”) . If you view this page on different browsers, operating systems, and devices (desktop/mobile), you’ll notice that it’s visually inconsistent.
I understand the desire for a textual check but the unpredictability of emoji appearance makes ✓✔︎ too similar to enable in good conscience. For example, if ✓ was ✕, we’d be having the same discussion about xX✕✖︎✖️.
If there’s anything else I can help calculate or do to facilitate DAO adoption, please let me know.
The things that would immediately benefit from the new normalization spec:
-
app.ens.domains: registration input, showing script of labels, beautified name, etc…
-
metadata: showing beautified names in the image/svg and properly assigning
 in marketplaces
in marketplaces
-
etherscan: beautified primary names
-
metamask: their ENS input needs a lot of work