What about Norse / Rune languages and characters ? The scripting is beautiful and while not being very “human readable” - the letters and words do look appealing and would look pretty nice on etherscan !
For example:
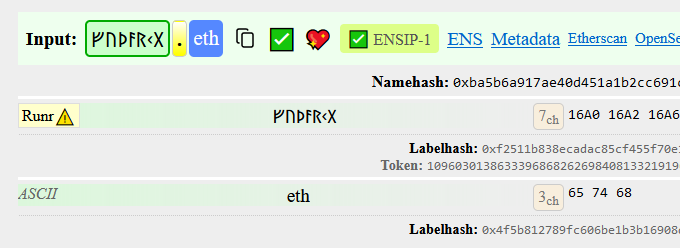
ᚠᚢᚦᚨᚱᚲᚷ.eth ?
What about Norse / Rune languages and characters ? The scripting is beautiful and while not being very “human readable” - the letters and words do look appealing and would look pretty nice on etherscan !
For example:
ᚠᚢᚦᚨᚱᚲᚷ.eth ?
Runic is allowed, however since it’s an excluded script, the label must be pure (and can only mix with emoji.)
Wow that link you provided on excluded scripts get pretty deep pretty fast ! Yikes ![]()
But essentially I can still go an mint Runic or other special characters and set the reverse records if desired ?
Along with cool shapes like this:
⏣⏣⏣⏣⏣⏣.eth
I love finding and minting these unusual ones that are so different but look so appealing on or when SIWE on various apps!
Sometimes I think having domains that aren’t so much “Human Readable, but “Human noticeable” is such a hugely overlooked area by most.
I particularly love signing in to one of my Opensea accounts using an emoji domain that I set the reverse record on a while back from this wallet -
0x21b8defe3b23e6d701f407fa94dc64fe206041b3
![]()
![]()
![]()
Keep up the good work man!
The following 2 ports are now 100% match (across 2.7m labels) with the JS implementation.
I submit a PR for a few minor updates to the ENSIP-15.
Not a spec change, but I’ve made a small update to my Resolver:
Names that were Emoji + ASCII used to appear as Latin (because ASCII is specifically 7-bit). However, I now separate these cases and show an overall summary for the name:
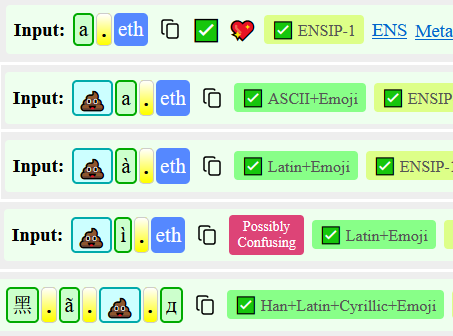
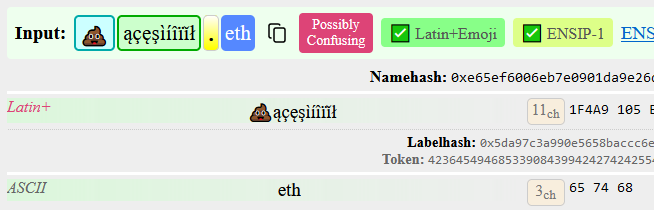
Names that are Latin but contain any of ąçęşìíîïǐł are now marked as “Potentially Confusing”. ENSIP-15 reduced the “modified ASCII space” from effectively infinite to a handful of characters, but there are still few marks that may go unnoticed:
![]()
This PR is still waiting for approval, although maybe it can wait for the pending Unicode update.
Unicode 15.1 will be released on September 12 (~2 weeks). I’ve built the library against the latest proposal files and ran it on all existing registrations:
Changewise:
Can we get the ENS Metadata Service to use the beautified result in the SVG and JSON?
Example: 9️⃣9️⃣.eth Resolver | Metadata
The <svg> rendering is the most important but "description" (and "name"?) can be changed as well IMO.
Note: modern mobile devices already force beautify system-wide.
I’ve been told Metamask is still having normalization issues. I was about to submit a PR to add ENSIP-15 support but encountered an issue with an older version of ethers. I talked to Ricmoo and the intention is to release a patch for ethers v5 with the latest ENSIP-15 support.
I recently upgraded my registration tracker which shows the most recent 1000 names under various perspectives:
Approved. In future if you add me as a reviewer I’ll be sure to see it sooner.
Thanks for approving the docs PR and deploying beautification in the metadata service.
I updated the ENSIP-15 spec files for Unicode 15.1.0. For implementers, there are no code changes required, just rebuild with the latest spec files.
As mentioned above, none of the Unicode changes impact any valid registered names.
I’m currently looking for some clarity regarding URL parsing, as a few projects have moved to Ada’s URL parser, which follows WhatWG, which suggested CheckJoiners true, which disallows ZWJ, which makes punycoded ZWJ emoji names invalid, and thus unreachable over DNS. Clearly there’s some confusion here as the major browser vendors don’t even agree on some punycode rules. This is an implementation issue not a Unicode issue, similar to how it’s perfectly valid to use IDNA with useSTD3 false to allow underscore according to UTS-46.
ens-normalize-python by NameHash is also updated with Unicode 15.1.0 and pass new tests.
Unicode 16 is next month. So far, it is just a spec.json update and no code changes are required. I’ll wait for the final data files to do analysis. Here is a diff if curious.
There are a small number of new emoji. Everything else is pretty typical. The most interesting new characters are in the Legacy Computing Supplement eg. the various game sprites.
[1FA89] () HARP [Emoji,Emoji_Presentation,Extended_Pictographic,Basic_Emoji]
[1FA8F] () SHOVEL [Emoji,Emoji_Presentation,Extended_Pictographic,Basic_Emoji]
[1FABE] () LEAFLESS TREE [Emoji,Emoji_Presentation,Extended_Pictographic,Basic_Emoji]
[1FAC6] () FINGERPRINT [Emoji,Emoji_Presentation,Extended_Pictographic,Basic_Emoji]
[1FADC] () ROOT VEGETABLE [Emoji,Emoji_Presentation,Extended_Pictographic,Basic_Emoji]
[1FADF] () SPLATTER [Emoji,Emoji_Presentation,Extended_Pictographic,Basic_Emoji]
[1FAE9] () FACE WITH BAGS UNDER EYES [Emoji,Emoji_Presentation,Extended_Pictographic,Basic_Emoji]
[1F1E8 1F1F6] (🇨🇶) flag: Sark [RGI_Emoji_Flag_Sequence]
Recently, I released a Go port. I plan on making a Rust port soon too.
Unicode 16 was released today.
I made all of the obvious changes and updated the corresponding files. As expected, no code changes are required, only the data files (spec.json and nf.json) need updated.
Unicode made some good changes regarding UTS-46. They starting mapping lookalike ASCII characters to actual ASCII characters (something ENSIP-15 already does). There are now all kinds of obvious mappings for characters like ,;:!?_ etc. They also [relaxed](https://www.unicode.org/reports/tr46/#Modifications) the UseSTD3ASCIIRuleslogic, which aligns with our decision to enable_and.
I’ll review the changes tomorrow, create a diff report, finalize the changes, and then everything should be good for another year.
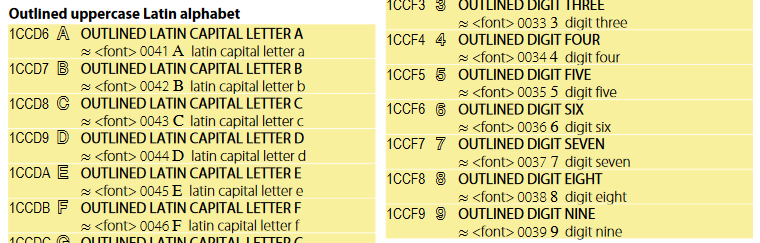
1.11.0 and 0 errors)16.0.0 and 0 errors for Library)Following the existing guidelines, I disabled most of the “Legacy Computing Supplement” and just kept the iconic sprites. I think the only decision is whether OUTLINED LATIN CAPITAL [A-Z] should be valid or mapped to a-z. The default is that they’re mapped and that seems correct to me. For reference, most of the additional a-z LATIN sets are mapped to a-z. The only a-z set ENSIP-15 allows is NEGATIVE SQUARED ![]() -🆉 because it contains emoji:
-🆉 because it contains emoji: ![]()
![]()
![]()
![]() .
.
$ → `)The following have been updated to 16.0.0
Unicode 17 is next month. It’s mostly just additional characters and emoji. For developers, the upgrade process will likely be: (1) pull the latest {nf,spec}.json and (2) rebuild.
I have a PR which goes over the latest changes, including a summary of changes, various diffs, and links to other resources. The draft Unicode files periodically change, so I’ll wait to do the final review closer to release.
Recently:
Amazing work as always @raffy
Of course you write Swift too ![]()
Have you got something cooking in the iOS space or was this purely for the ecosystem? ![]()
PR: Unicode 17 has been ready for few days. I will merge tomorrow and notify the other library developers. With a few adjustments, I was able to cause no registered names to become invalid. I also caught a few things that I missed from 16.0.0 but luckily had no registrations. This shouldn’t have any noticeable effect on the ecosystem and adoption can be slow since normalization precedes platform support which typically comes 6-12+ months later.