[Repeating/summarizing some stuff from earlier posts. This is just my opinion.]
I think everything that normalizes according to my ENSIP is legal. This is maximum compatibility with the previous spec and IDNA 2003 (and punycode transform), fixes ZWJ and emoji, can be implemented in ~30 lines of code, and decouples the implementer from needing to parse the Unicode spec (just use 2 data files referenced in my ENSIP).
The only future change to the spec should be adopting new Unicode characters (and potentially adding mappings for things that can’t be fixed through validation, like Arabic Numerals or Hyphens.)
I am fully aware there are valid names that are insane/unsafe but I think this was the best compromise w/o getting into the weeds (imagine the hyphen debate above but for hundreds of characters.)
The next thing that I wanted to do—I’m not sure if others agree—is validation/safety/whatever (I’m not sure what to call it). I would like some kind of UX for unsafe names (warning, etc.) Validation is simply checking if a normalized name is safe. Since all colored emoji are safe? (a potential question for community), validation only needs to address the textual parts of a name. Most validators should be single script or minimal script combinations (X+Latin+Common). There are some characters (Common script) that can likely be mixed with any script, which include non-colored emoji and pictographs.
IMO, one should always be able to ignore any validation and use any name that normalizes according to the spec. Validation is primarily for user-input. I envision a contract function that only rejects invalid names, and another function that rejects invalid AND unsafe names.
The easiest validator is DNS/Basic which covers most names. The next validator would be Latin (which requires some debate about confusables). Once you have that, you can add all the languages that are X+Latin (more debate about conufsables). Additionally, there would be Basic-equivalents in other scripts (possibly using Unicode exemplars).
I don’t think all validators need to be same level of “safe” and this potentially could be a feature. An earlier idea was that each validator should have a ranking. For example, an advanced user, wallet, or application could specify the set of acceptable validators.
There’s nothing wrong with validator overlap either. For example, the Basic validator is (likely) a subset of the Latin validator. And the Latin validator is (almost) a subset of the Japn+Latin validator. However, as you increase validator coverage, you increase confusability.
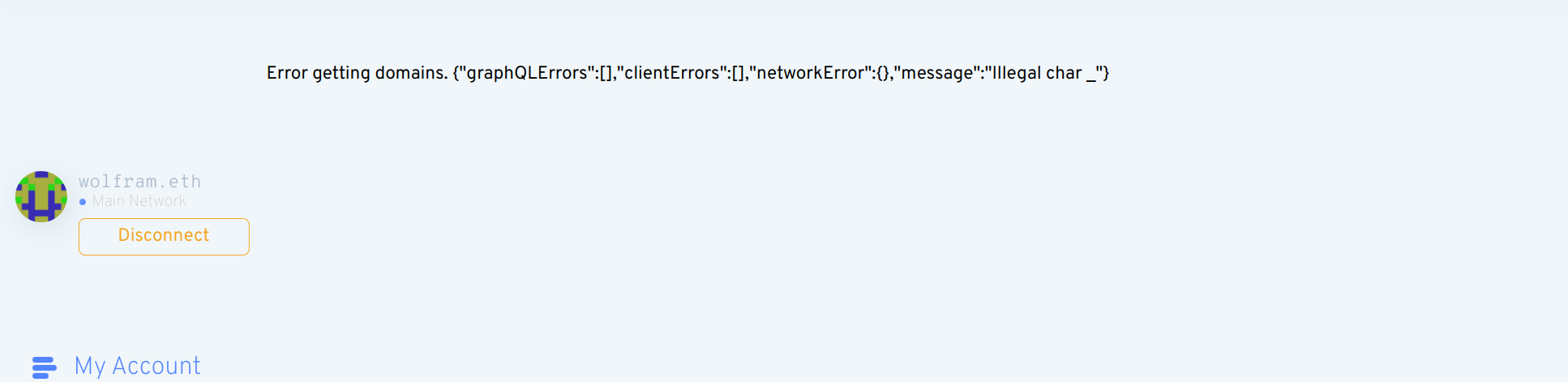
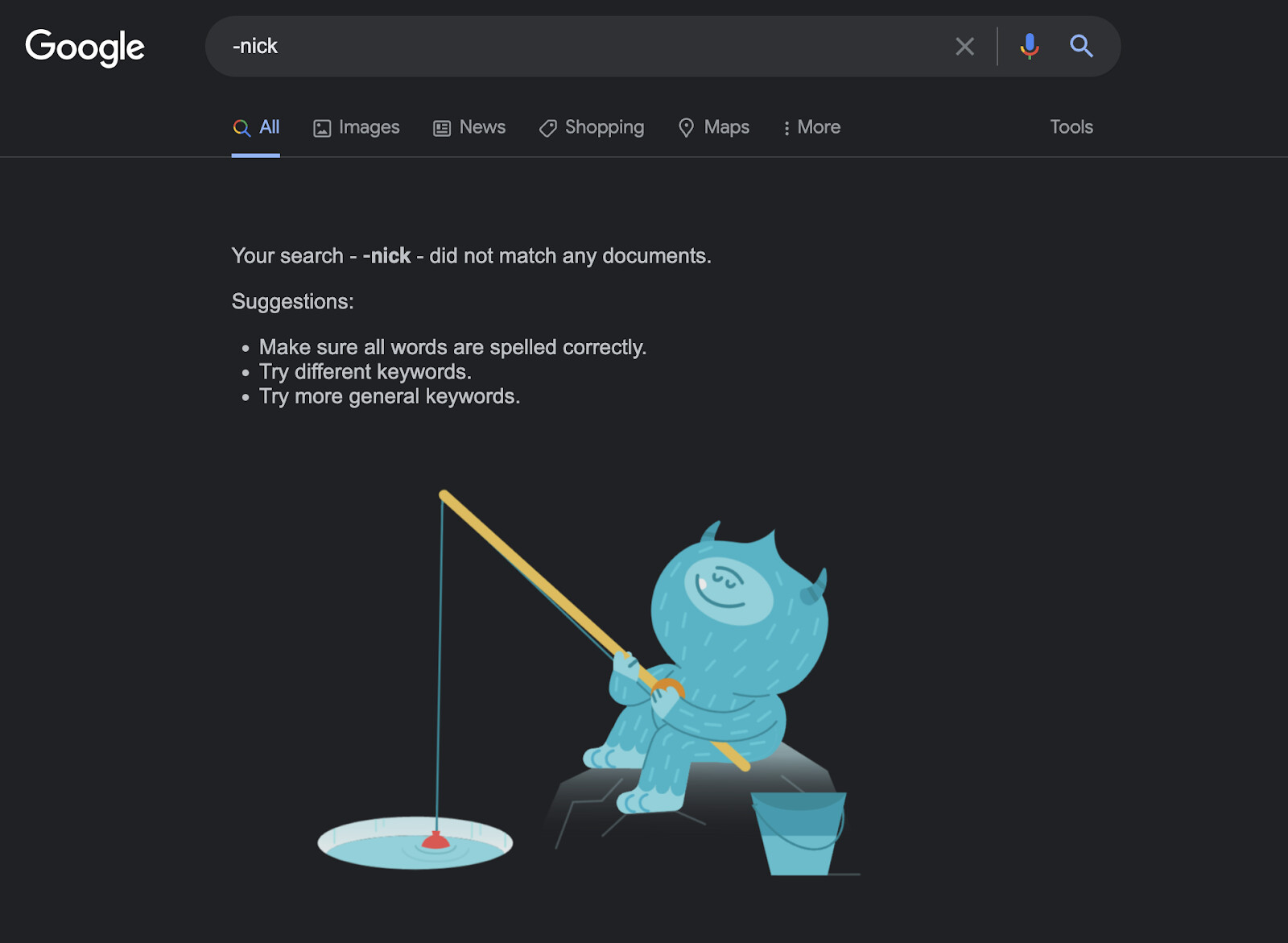
Specifically for the Basic validator, we discussed having a restriction on underscore (leading only?) and hyphens (repeated?). Personally, I think the Basic validator should imply maximum safety (under the assumption that ASCII is unique and its confusables like "1lI" are grandfathered-in.) I think something like 0-2 leading underscores and 2-or-fewer adjacent dashes would fit this criteria. However, I don’t see any reason why we can’t have another validator that allows more underscores or hyphens, I just wouldn’t consider it Basic.