Understood. I’ll leave this as the last change. There’s a bunch of things that have no right answer but shouldn’t be left as-is either. We can revisit them later.
6 Likes
I know this is lazy… especially given the amount of thought that has gone into these discussions, but this thread has gotten a little bit unmanageable and I am struggling to discern where things are at.
Could anyone offer a high level summary of the current position re normalisation?
Many thanks.
ensip-norm/draft.md at main · adraffy/ensip-norm · GitHub seems kept updated fairly regularly
4 Likes
I think I got ens-normalize.js to a stable state. There’s still stuff to do, but there’s enough code that it’s just a matter of choosing the best ruleset, updating the positional logic, and recompiling the library. For example: if we just want to fix emoji and ZWJ, and enable $ and _, that’s a trivial modification to the rule files.
I’ve been keeping my ENSIP in-sync but the last batch of changes still needs incorporated.
If you want to wrap your head around my suggested changes, here are the places to look:
-
/derive/rules/ — ENS modifications to Unicode Data
- The file names should be self-explanatory
-
/derive/make.js — compiles Unicode Data + Rules into a specification
- Imports IDNA and Emoji Sets according to ENSIP
- Output log.txt
-
/src/lib.js
-
ens_normalize_post_check()— positional logic -
process()— according to ENSIP
-
For the last couple things I was working on:
-
Mapped all the circled letters/digits to ASCII except for the squared negative letters which are partially emoji already. This is probably controversial but some compromise is necessary. These could also be disallowed until a decision is made.
- ❻vs➏ and ⓺vs➅ and 🅒vs🅲.
- 🄰 is already mapped to
a -
 is an emoji (negative squared a)
is an emoji (negative squared a)
-
Disallowed:
- Braille (until we make a decision about it)
- Box Drawings
- I made another pass at small punctuation (periods, commas, brackets) but still more remain
- Near-duplicate symbols that have emoji equivalents
- Characters with poor platform support
-
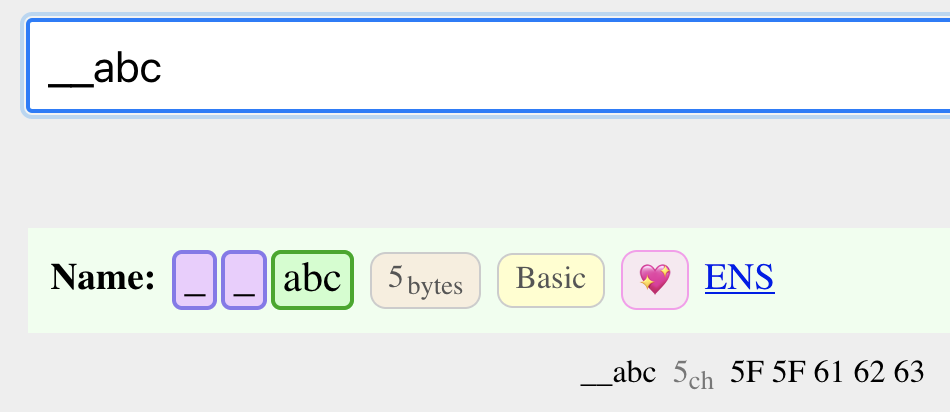
I created a subclass of the Valid characters called Isolates. These characters work just like normal characters, except they’re not allowed to be modified by a combining mark. All Emoji are effectively Isolates. I’ve marked characters like
_-’as Isolates. All non-emoji pictographs are Isolates. Anything symbol-like should probably be marked as Isolate. I show them as purple in the demo. This also makes them easier to count.
-
I restored the Mixed- and Whole-script confusable logic for Latin/Greek/Cyrillic (with Latin-preferred since it overlaps with ASCII). Other scripts are left unrestricted. My personal opinion (expressed earlier in this thread) is that the Unicode confusables are incomplete and inconsistent (too strict in some cases, too loose in others.) In the future, we could add a whitelist to relax some of these confusable categories.
-

coinbasе coinbаsе coınbase cоinbase -
bitcoın bitcοin bitcоin bitсoin bitсоin bıtcoin bıtcoın bіtcoin bіtcoіn bіtсоin
-
-
Preliminary Damage Reports:


I think we should start a new thread with outline summary for this thread.
6 Likes
I started a new thread.
7 Likes