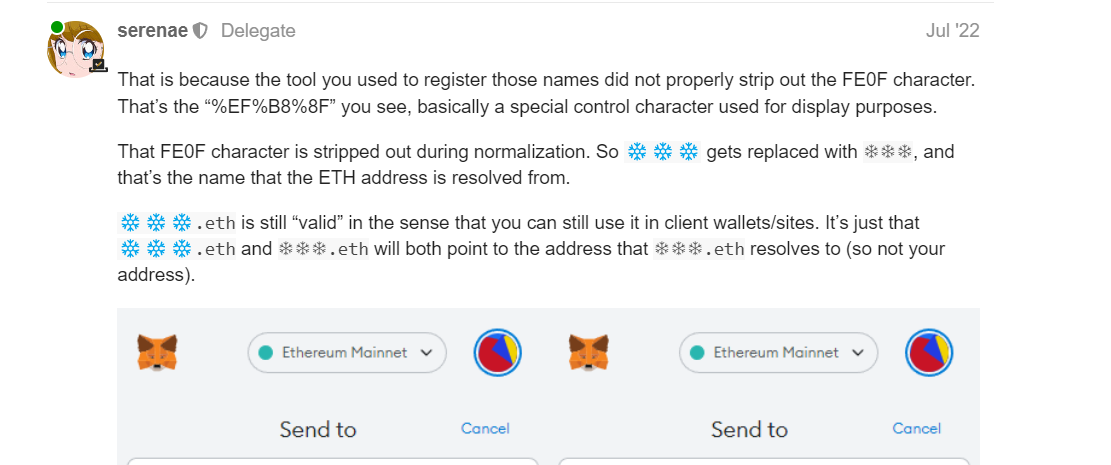
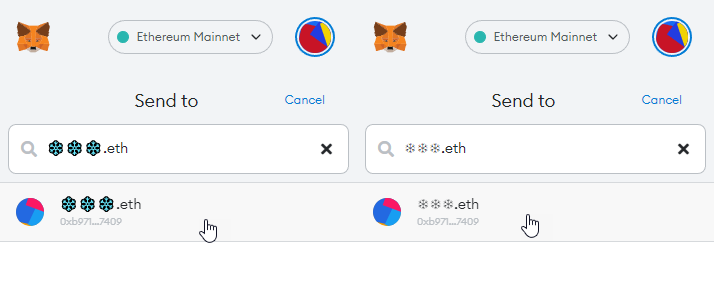
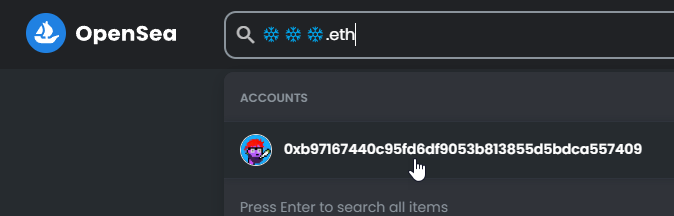
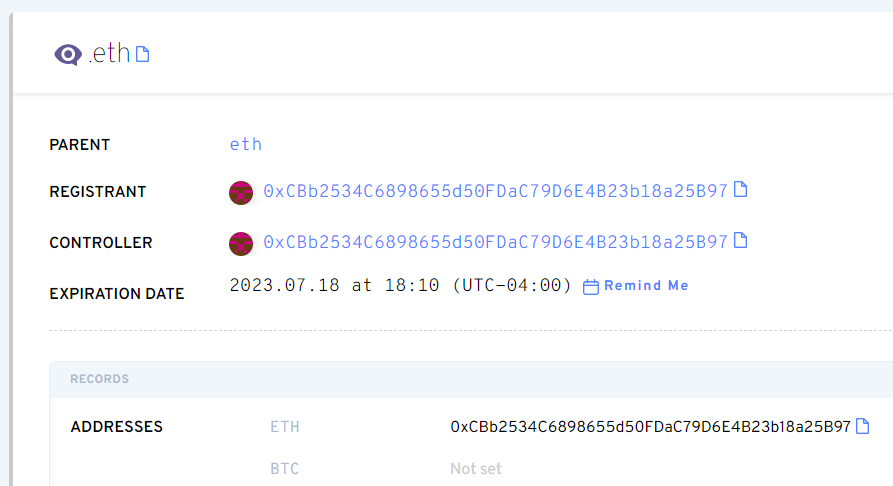
Hi ENS DAO, I wanted to bring your attention to an important matter.
I’d observed it previously that emojis like ![]()
![]()
![]() have different sequencing in the official unicode releases than from what the normalization takes as official. This is because the FE0F part of the sequence is stripped off, as it contributes nothing to the name as per @raffy
have different sequencing in the official unicode releases than from what the normalization takes as official. This is because the FE0F part of the sequence is stripped off, as it contributes nothing to the name as per @raffy
Consider this for an example -

in this you can see only the first sequence is (marked) qualified by Unicode and the rest are marked as unqualified or minimally qualified. But the normalization only happens for the 4th one which is marked as unqualified in this unicode 15.0 document release.

Same is the case with the rest of the emojis above and many more. Raffy told me that the FE0F part has been removed because it does not contribute anything to the sequence and it’ll remain the same regardless. Some examples like the ![]() and
and ![]() as well. In this case too, doesn’t matter which you register the normalisation caters to only the older version, which is
as well. In this case too, doesn’t matter which you register the normalisation caters to only the older version, which is
![]() .
.
In the above ![]() case, it should have been a 5 character emoji, costing 160$ instead of 640$ + the current one where the normalisation points should have been invalidated. But it’s not the case since it was already registered when ENS was following the 2003 spec of unicode. Though it was later noticed that there were many anomalies with this due to FE0F, as previously believed, FE0F was not unnecessary and was imp in some emoji versions. But ENS ignored them and only normalised the non FE0F versions.
case, it should have been a 5 character emoji, costing 160$ instead of 640$ + the current one where the normalisation points should have been invalidated. But it’s not the case since it was already registered when ENS was following the 2003 spec of unicode. Though it was later noticed that there were many anomalies with this due to FE0F, as previously believed, FE0F was not unnecessary and was imp in some emoji versions. But ENS ignored them and only normalised the non FE0F versions.
There has been some discussion around this as well like -
and this one too, which has never been adressed by the DAO even though the problem is legit -
I had a chat with @raffy to understand what’s happening here, since in the above discussion Raffy too was advocating on including all ZWJ and FE0F sequences which are in the newer versions. But now his stance is also to let FE0F be stripped off.
This had already created some issues previously but had been ignored by the DAO in the pretext that the individual is not registering the ENS from the main frontend. My argument against this is that they don’t need to. I’m able to use AAVE or UNI without using its main frontend/app. One must be able to register to an emoji from the contract itself without depending on the frontend, just by referring to the Unicode version release and be sure that the Fully qualified version must be normalised and the unqualified one must not be. It’s an over assumption that someone who would be registering an ENS from the contract would also be reading the governance forums for something as basic as inclusion of FE0F, the version of which unicode clearly marked as VALID but ENS marks as INVALID.
You should ofc not break the previous Emoji registrations for this, but it sure can be corrected for the new ones. Consider this example -
![]()
this was released last year ('22) reading this you’d assume ENS may have opted for the first one to be the correct normalised sequence, since unicode marked that one as fully qualified (Note:marked). But it’s not so, and therefore instead of it being a 4char emoji, it’s a 3 character emoji, same thing but now costs $640 instead of $160.
One should be able to look up unicode doc, find the unicode sequence, find read that ‘this one’s fully qualified’ and register that from the contract without using the app frontend. ENS should not be imposing their own frontend, making it seem more centralised. One can still register the FE0F version of the emoji but since normalization doesn’t pick that up, it’s a waste of money and makes no sense to not follow what unicode terms as fully qualified. We’ve also already observed some anomalies that it caused in previous versions like the poop emoji and the snowflake one.
Now the next argument is why even change that now that it’s working - my main take on this is, the thing that should ideally cost me $160 or $5, costs me $640. It sure brings more revenue to the DAO but as a user I’m getting rekt. Even if I use the main frontend, it doesn’t solve the problem, the cost remains the same. ![]() Therefore what @raffy mentioned as ‘it doesn’t change anything’ is wrong, it does reduce the cost for the end user to register these.
Therefore what @raffy mentioned as ‘it doesn’t change anything’ is wrong, it does reduce the cost for the end user to register these.
Moreover there are more examples, like in this one, I’d just need to register the first emoji as min 2 emojis and it’d take 4 char and cost me 160$ but now it costs me 640$ and have to register min 3 emojis, which only gets normalized to the first version and ignores the 2nd version altogether.
![]()
And in this, both are 4 char emojis for what unicode ‘marked’ as fully qualified, but ENS ignores them and goes with the 3 char ones which are marked as unqualified by unicode.
We sure cannot break previous names but we can improve this for the newer emojis involving FE0F sequence. Apparently 578 more emojis are to be released and 100s of them use FE0F sequence in them in the fully qualified version of the sequences. If the current FE0F sequence stripping is not removed it would keep costing more to register normal emojis like those and furthermore keep catering the marked ‘unqualified’ version of the unicode sequence.
It’s been an inefficiency on the ENS and Unicode’s end, but it can now be corrected atleast by ENS. DAO won’t earn an extra $1mm with this FE0F stripping, moreover not doing so is less user friendly and favors the DAO more than its community.


Open to a fruitful discussion where we not only think from the DAO’s perspective but also think from users’ pov keeping the ethos of decentralization in mind. Normalization is the main bottleneck here and partly contributes to a centralized approach, but one should be able to look into unicode releases, find the ‘marked’ FULLY QUALIFIED sequence, register that from the contract w/o main frontend and be sure that the normalization won’t be anything crazy so to ignore a part of the sequence(FE0F) and elevate the registration and renewal fee.
Tagging others as well who have been actively taking part in this topic previously -
@serenae, @nick.eth and also since we’re discussing ENS fees as well here, tagging @vbuterin for his take from this blogpost in https://vitalik.ca/general/2022/09/09/ens.html
edit:spelling