ENS on Swarm
Authors: Viktor Toth, Viktor Tron
Introduction
ENS enables name resolution based on the DNS address structure in a decentralized way. Its main logic and functionalities are defined in smart contracts, thus the system is meant to be deployed on EVM-compatible blockchains, additionally it is extended by centralized use-cases such as EIP-3668. Various workflows exist which define how to interact with these smart contracts functions initiating the requests from dApps.
In this document, we would like to offer an off-chain architecture to the same use-case, on the P2P storage network Swarm. The proposal can be used in three ways:
- an alternative feature for off-chain ENS resolvers,
- for regular user record updates,
- putting the whole application logic off-chain.
Solutions for Current Architecture
This proposal suggests solutions for the biggest pain points of the current architecture:
- how to significantly decrease the fee for write operations
- how to improve the availability of the service.
We argue that a solution based on a decentralized off-chain resolver is called for. Below we elaborate this objective and present a full-blown name resolution service handled completely off-chain yet in a cryptographically provable way allowing for trustless provision in a decentralized environment.
Identity Addressing
In this new architecture the data is identity addressed, meaning that only the uploader’s Ethereum address and an arbitrary, consensual topic are required to calculate the address of the data. Technically, it leverages the Single Owner Chunk (SOC) based Feed concept of Swarm Network. SOCs have the following structure:
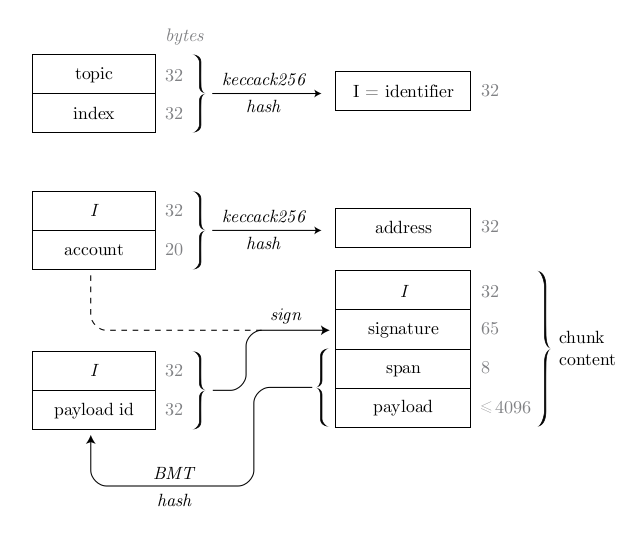
The Single Owner Chunk can wrap any chunk (span + payload) that can determine any length of data. This data can be labeled by the uploader (usually defined by some consensus laid out by dApps) which is expressed in the Identifier (I). The signature consists of an Ethereum signed message of these two: the hash of the identifier and the content address of the wrapped chunk.
Since the signature is signed by the uploader, the SOC address can be attested by recovering the Ethereum address of the uploader and hash that together with the Identifier. If one gets the same result as the SOC address prequested, then the SOC is valid. All this forms an address space that can be only written by possessing the corresponding private key to that address.
Feeds can be implemented by SOCs using a convention that the Identifier results from two parts: a topic (that has the same purpose as the Identifier) and an index, in order to differentiate different versions of the same topic. This allows mutable addressing where knowing the Source of the Information, the data identifier and the indexing schema any possible data address can be calculated on client-side, before lookup. The most straightforward way is to have sequential indexing that is supported on API and on JS side as well. The index can be anchored to the time that leverages the fact that the present time is known, thereby the maximum value of the index set is also known. Epoch-Based Feeds and the Fault Tolerant Feed Streams are indexing schemas and lookup methods and act as a blueprint to handle Swarm Feeds. The latest can be used to have O(1) lookup time of Feed data.
User Record Handling
In the first step, let’s check how all user records/metadata can be handled and found using the concepts above.
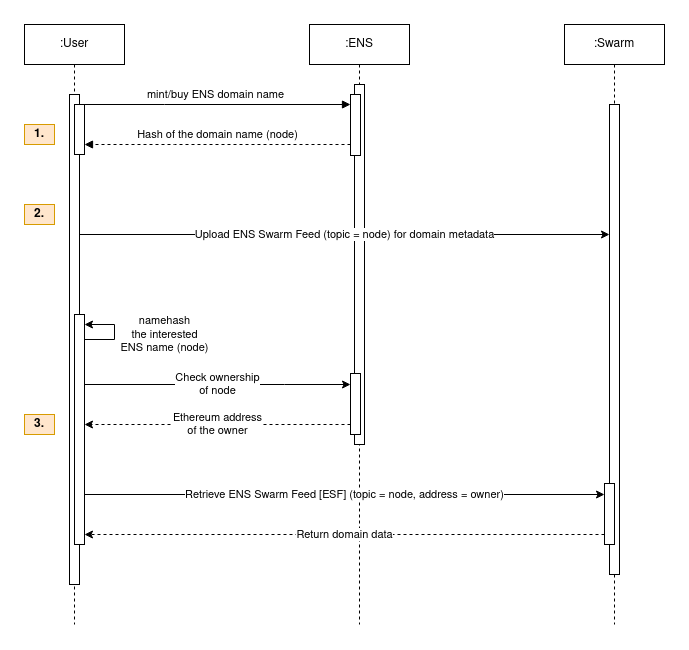
The 1st operation remains the same where the user acquires a node in the ENS Registry. But instead of setting up a new Resolver contract, the records can be uploaded and versioned off-chain (2nd). It is cheaper than managing the metadata on-chain (see #Uses section on Get BZZ Token - Swarm) and faster because it does not need block finalizations.
The last operation shows how this uploaded data can be downloaded by another user: retrieve the owner’s Ethereum address from the ENS registry and use the calculated node as topic of the feed, in which the latest version can be looked up based on the feed type.
Moving ENS Registry Data Off-Chain
It is possible to move the ENS Registry data off-chain as well. In that scenario, the owner of the registry maintains a service feed where the topics equal to the nodes again, but it stores Registry related information (owner/TTL properties) instead of resolver records. This service feed can be extended with other information too for the off-chain resolver use-case that also adds resolver related metadata in the same payload.
DApps are interacting with ENS by hard-coding its contract address in the source code and performing actions by its outlined logic. The trusted point, in this case, is the contract address itself which, for the above architecture, would be the ethereum addresses of the TLD service feeds. These addresses can be registered also under a smart contract that lists all trusted actors. One aspect of the model is not required, namely to register nodes in the TLD service feed because this responsibility can be delegated to the corresponding subdomains (e.g. host.alice.eth can be listed only under the service feed of alice.eth). Nevertheless, TLDs can aggregate nodes from feeds of descendant domains. This also implies that one must not look after any resolver, just obtain ownership of the domain chain that can start from the TLD. Based on this, if one wants to obtain “resolver” a node (its owner address), they can do virtually the opposite of ENSIP-10 Wildcard resolution. First let’s define a function canonicalDomains(domain) that returns domains of the passed parameter starting from its TLD or a domain of which address is known and supports off-chain operations (e.g. canonicalDomains(“host.alice.eth”) → [“eth”, “alice.eth”, “host.alice.eth”] ). Then one applies the following procedure:
- Initiate variable
ownerAddressto the default TLD owner address. - Iterate on elements in the canonicalDomains array (namehash(element) = node) trying to find feed records for all subsequent domain nodes concurrently. The process results in at least the one child domain having an owner record that can be used to continue the iteration. Otherwise it must throw an error.
- If the resolver record was retrieved by a service feed, attest it back on the owner’s feed.
Because every Feed has an out-of-the-box signature on the data that it carries, users can wrap the commitment from the parent domain’s service feed about their ownership above the node that they manage. This information can be optionally placed in the same payload (since the smallest data unit is 4kb on Swarm) or by introducing a new topic construction that holds this data such as topic = keccak256(node + ‘witness’). Nevertheless, for full attestation one must check the latest versions of the corresponding ESFs up to the TLD if one wants to be sure the domain is owned by the user at the moment.
Extras
To list all handled subdomains of a domain, one can use data-structures meant to represent indexes, such as Mantaray or POT. Both have native implementations on Swarm, offer logarithmic retrieval in the size of the index, allow prefix searches, iterations, preserve history.
POT is optimized for cheap insertions and updates and amortized retrieval and update performance over recently updated records (which virtually auto scales for frequently updated content).
As a bonus, communication with the services live on Swarm can be done in a decentralized way (e.g. initial request for name registration) without the need for additional components using Graffiti Feeds or PSS messaging. This would allow serverless registries..
Swarm ensures permissionless publishing and access to the data and automatic scaling of popular content.
Implementation
The development of this architecture can happen by JS developers that are familiar with the concepts of ENS and can interact with Swarm (feeds/SOC).
My personal experience is that it is the fastest to start with the libraries first. There are two main components: (1) user/revolver handler and (2) registry handler. For initiative, the interfaces of these should be designed by the applicants and after choosing the best alternative, the logic, documentation and testing could be done. The components can be placed in a single library (e.g. ens-swarm-js) where the functionalities are implemented in different phases as it is numbered.
In order to try out the concept, a website like ENS App that utilizes the library mentioned is also necessary. In the alpha phase, this could be implemented only in one domain (e.g. swarmens.eth) and after that it could be extended to other domains as well.