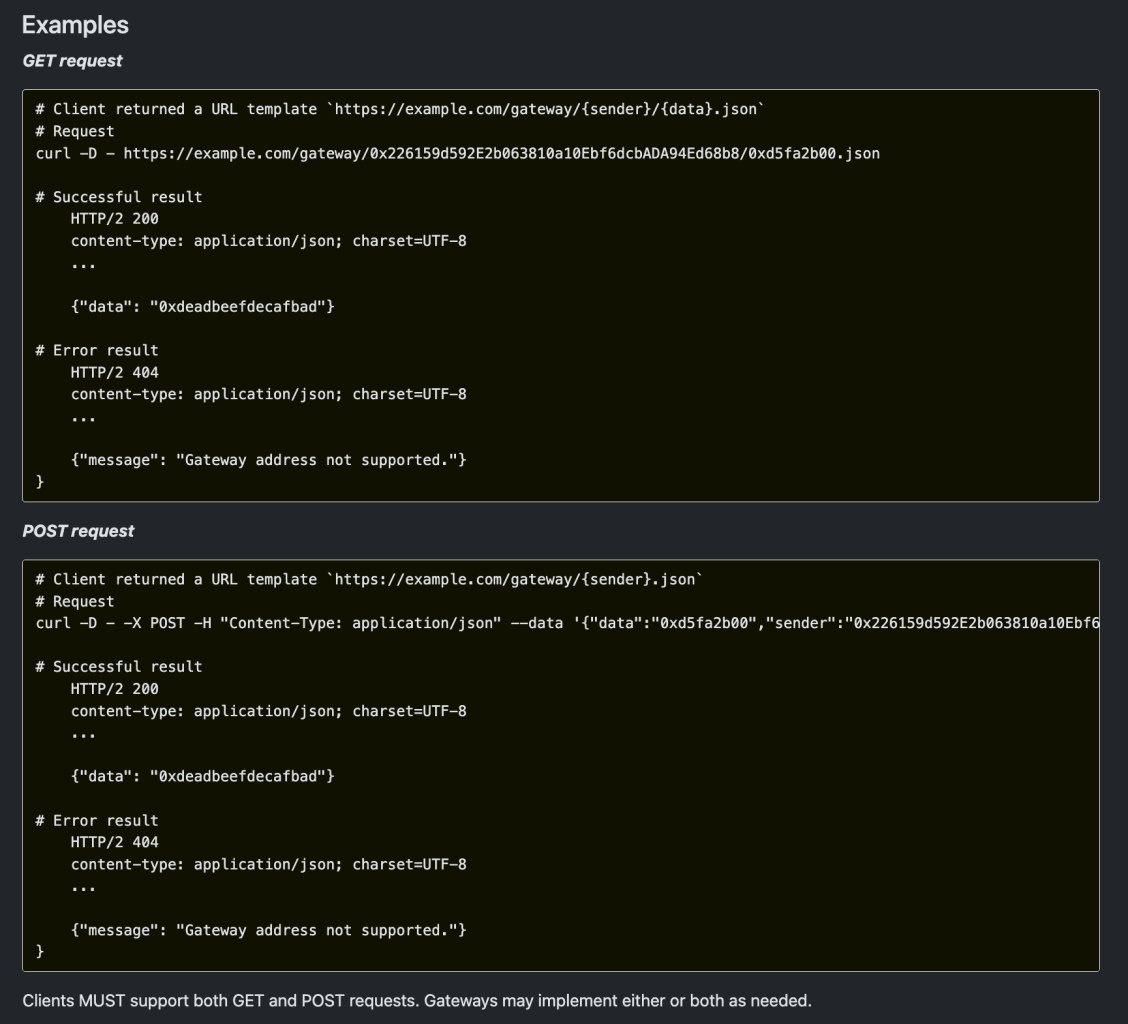
I’ve tried a few times to write this post but I keep getting lost trying to account for various possibilities and consequences. Instead, I think it’s better to just describe how I think this should work and see if anyone agrees.
My current thoughts for making ENS work across the EVM ecosystem
tl;dr
always start resolution from L1 (independent of dapp/wallet/etc)(free)- on each L2, create Registry at
0x00000000000C2E074eC69A0dFb2997BA6C7d2e1e - on each L2, create Registrar for
{chainName}.eth(eg.*.op.eth) - store reverse names on L2 exactly like L1
- deploy BridgedResolver on all chains (calls registry on another chain via ENSIP-10++)
- set BridgedResolver on L2 [root]
- set BridgedResolver on L1 for each
{chainName}.ethsubdomain use BridgedResolver to connect reverse records to corresponding chains(free)use claimable{owner}._ownedto enable L2 storage for L1 names
Forward resolution should always start from L1 registry. For developers, the ENS client provider should be decoupled from the dapp provider. This will extend the ENS we use today to every EVM chain without any additional changes.
Edit: This is no longer necessary with a wildcard on the L2 [root] (see below).
Forward address resolution should be chain-aware. This has many input representations (eg. op:raffy.eth) but effectively specifies the coinType (and fallback behavior) based on chain.
-
L1: (
raffy.eth, 1) → addr(60)
L2/op: (raffy.eth, 10) → addr(614)
L2/arb: (raffy.eth, 42161) → addr(9001) -
If we use fallback, nearly all EOAs would likely use addr(60):
L2: (raffy.eth, 10) → addr(614) || addr(60) -
Or, we could define a universal coinType for “any evm chain”:
L1: (raffy.eth, 1) → addr(60) || addr(any)
L2: (raffy.eth, 10) → addr(614) || addr(any) -
Or, constantly remind the user on L2 to update their addr(60) when they set their chain-specific coinType.
Reverse resolution should be native. This requires a reverse registry contract on each L2. This can use the existing ReverseRegistry and NameResolver tech.
Reverse address resolution should be chain-aware.
-
L1 or L2:
resolve("51050ec063d393217b436747617ad1c2285aeeee.addr.reverse")does normal thing -
L1 or L2:
resolve("51050ec063d393217b436747617ad1c2285aeeee.{chain}.reverse")is a{chain}.reverseWildcard that uses BridgedResolver to access another chains reverse registry. -
Fallback could be implemented in the ENS client or helper contract (eg.
*.any.reverse) -
L2 could directly query the L2 registry for reverse records if no fallback is required.Get this for free.
(Optional) Acquire 1-4 character names for each L2’s blessed registrar.
- Example:
{op/o, arb/a, base/b, poly/p, avax/c, ...}.eth
Cross-chain names could be bridged using an extension of ENSIP-10 where a new optional behavior target() returns the chain where the resolution could happen natively and basename replacement.
Extended ENSIP-10
// change: ens (registry) is provided
// change: check [root] resolver
function getResolver(ens, name) {
let currentname = name;
while (true) {
const node = namehash(currentname);
const resolver = ens.resolver(node);
if(resolver) return [resolver, currentname];
if (!currentname) return [];
currentname = parent(currentname);
}
}
// change: ens (registry) is provided
// new: if the resolver is ENSIP-10 and supports BridgedResolver extension, do a native call
function resolve(ens, name, func, ...args) {
const [resolver, resolverName] = getResolver(ens, name);
if(!resolver) return null;
const supportsENSIP10 = resolver.supportsInterface('0x9061b923');
if(resolver.supportsInterface('0x9061b923')) {
const node = namehash(name);
try {
const [chain, basename] = resolver.target(namehash(resolverName));
const alt_ens = ensForChain(chain);
let alt_name = name.slice(0, -resolverName.length);
if (basename == '_owned') basename = join(ens.owner(node).slice(2).toLowerCase(), basename);
alt_name = join(alt_name, basename);
return resolve(alt_ens, alt_name, func, ...args);
} catch (ignored) {
}
const calldata = resolver[func].encodeFunctionCall(node, ...args);
const result = resolver.resolve(dnsencode(name), calldata);
return resolver[func].decodeReturnData(result);
} else if(name == resolverName) {
return resolver[func](...args);
} else {
return null;
}
}
function ensForChain(chain) {
// return registry contract for each known chain
}
interface IBridgedResolver {
function target(bytes32 node) external view returns (uint256 chain, string memory basename);
}
contract BridgedResolver {
function setTarget(bytes32 node, uint256 chain, string calldata basename) authorized(node) external;
}
There only needs be one deployment of the BridgedResolver per chain since the target can be parameterized by basename of the wildcard. If the ENS client is unaware of the chain, the resolver would handle the request using CCIP read via EVM gateway.
I included the ability to modify the basename, so the op.eth registry tree could be used before short .eth names are enabled on mainnet. This would allow raffy.[op-bridge.eth] to wildcard bridge to raffy.[op.eth] and would allow raffy.[op] or any other other TLD to also bridge into the same raffy.[op.eth] node.
Special case: if the basename is _owned, the basename becomes {owner}._owned (see below).
- Register
op.eth ENSRegistry.setResolver(namehash("op.eth"), BridgedResolver.address)BridgedResolver.setTarget(namehash("op.eth"), 10, "op.eth")
eg. L1:*.op.eth→ L2[10]:*.op.eth
The BridgedResolver could also be used for the reverse record (10.reverse) example above:
- L1:
BridgedResolver.setTarget(namehash("10.reverse"), 10, "addr.reverse")
L2:BridgedResolver.setTarget(namehash("1.reverse"), 1, "addr.reverse")
eg. L1:*.10.reverse→ L2[10]:*.addr.reverse
eg. L2:*.1.reverse→ L1:*.addr.reverse
Each L2 should have a Registry contract. This contract is almost never invoked directly since resolution starts from L1. Ideally this should be a fixed address and shouldn’t be the same as the L1 registry.
[root]← resolver = BridgedResolver(1,"")reverseaddr51050ec063d393217b436747617ad1c2285aeeee
eth← resolver = nullop← NFT registrarraffy← Tokenized
_owned51050ec063d393217b436747617ad1c2285aeeee
Deploy a L2 registrar for claiming {label}.(op|arb|...).eth. Should probably use something like NameWrapper. This would work like .eth registrations on L1. This could have a registration fee and expiration.
Deploy a L2 registrar which lets anyone claim Use {owner}._owned. This would not be tokenized. You could build anything off this node, but since resolution works for L1, this node isn’t reachable directly since resolution starts from L1.addr.reverse instead.
Name → Resolver Examples
-
L1 name:
raffy.eth→ PublicResolver -
L2 name:
raffy.op.eth→op.ethBridgedResolver(10,op.eth)
→ L2[10]:raffy.op.eth→ PublicResolver -
L1 name w/L2 resolver:
raffy.eth→raffy.ethBridgedResolver(10,51050ec063d393217b436747617ad1c2285aeeee.addr.reverse)
→ L2[10]:raffy.51050ec063d393217b436747617ad1c2285aeeee.addr.reverse→ PublicResolver -
L1 name w/L2 resolver:
sub.raffy.eth→raffy.ethBridgedResolver(10,51050ec063d393217b436747617ad1c2285aeeee.addr.reverse)
→ L2[10]:sub.raffy.51050ec063d393217b436747617ad1c2285aeeee.addr.reverse→ PublicResolver
Address Examples
- L1 name: (
raffy.eth, 1) → PublicResolver → addr(60) - L1 name: (
raffy.eth, 10) → PublicResolver → addr(614) - L2 name: (
raffy.op.eth, 1) → BridgedResolver → PublicResolver → addr(60) - L2 name: (
raffy.op.eth, 10) → BridgedResolver → PublicResolver → addr(618)
This setup would allow stuff like:
- L2 wildcard:
- Register
test.op.ethon L2 - Set it as a custom wildcard on L2
- From anywhere, resolve
sub.test.op.eth
- Register
- L2 wildcard mirror of .eth on L1 (same tech used on [root] of L2)
- Register
eth.op.ethon L2 - Set it as BridgedResolver(1,
eth) - From anywhere, resolve
raffy.eth.op.eth- L1:
raffy.eth.[op.eth]→ BridgedResolver(10,op.eth) → (10,raffy.eth.op.eth) - L2[10]:
raffy.[eth.op.eth]→ BridgedResolver(1,eth) → (1,raffy.eth) - L1:
raffy.eth→ PublicResolver
- L1:
- Register