Hello!
We are leading a project sponsored by the Metagov Working Group to create a protocol for storing organizational metadata on ENS. The end result will be a standardized way for any kind of organizational structure to be represented as records stored under an ENS name. The most immediate use case will be for DAOs who want to offer transparency and security in sharing information about their organizational structure.
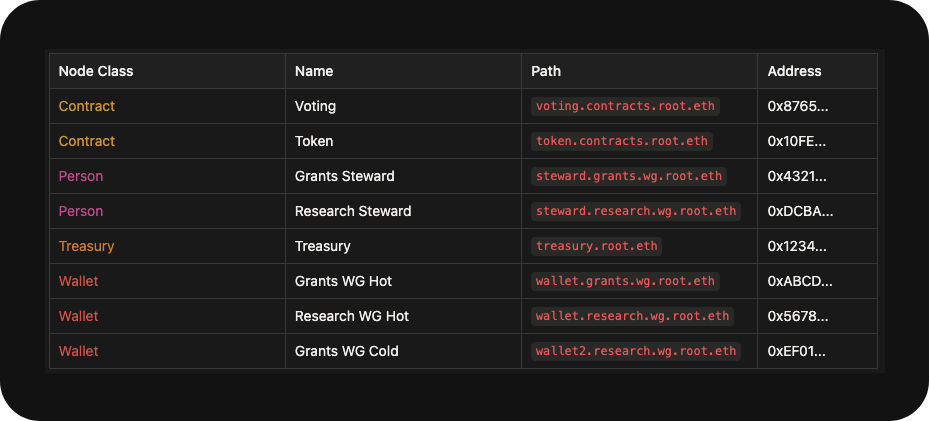
Storing this data on-chain would allow DAOs to:
- Present an official, public list of all their contract addresses (treasury, voting, governance tokens, etc)
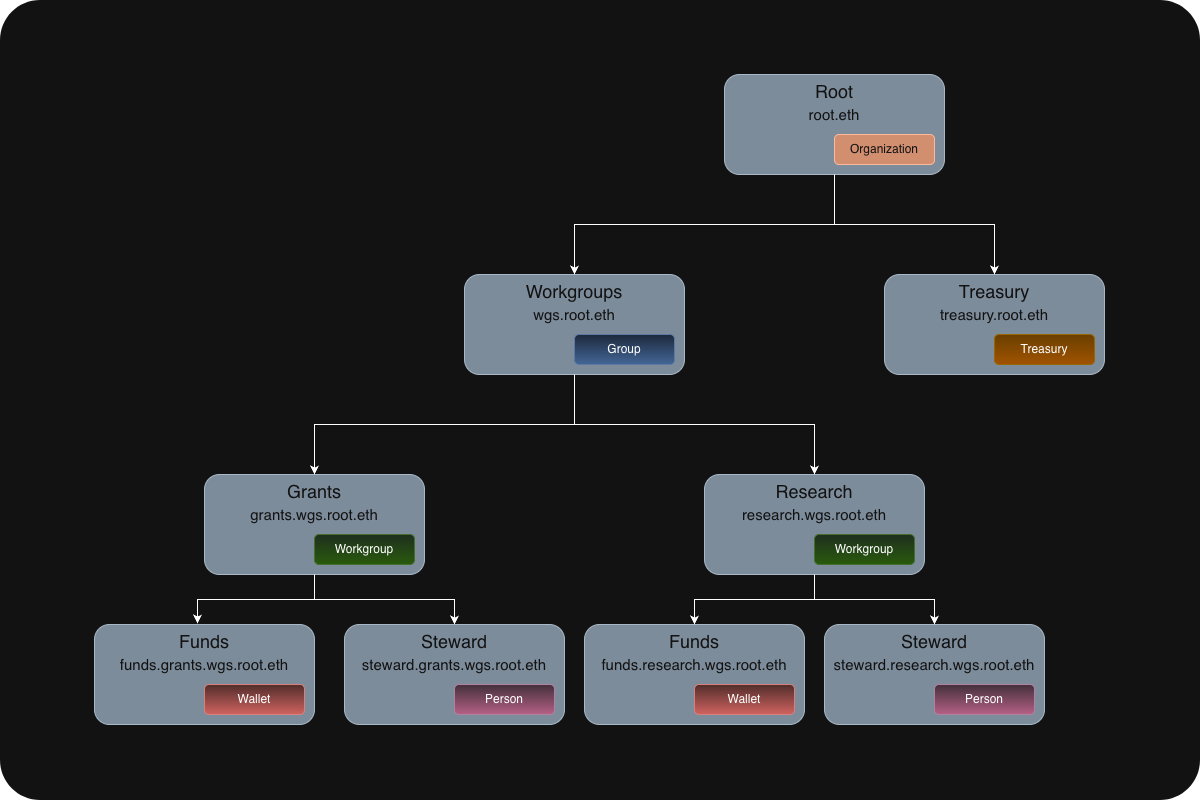
- Describe the organizational structure of working groups, councils, committees, and any other bodies that are sanctioned by the DAO.
- Publicly acknowledge paid and/or unpaid delegates, and create a space for them to publish delegate statements, conflict of interest disclaimers, or other important information.
- Publish information that is required for regulatory reasons, such as contact details for an associated DUNA or legal entity, limited liability disclaimers, etc.
DAOs already use ENS names to represent themselves in a trustless/decentralized way, and for the DAOs whose ENS records can only be updated as the result of a DAO vote, organizational records will be considered the single source of truth.
What to expect
The initiative to develop this protocol is being led by Lighthouse Labs. The project was previously discussed here. We plan to produce a technical spec that can be published as an ENSIP or EIP, with a PoC implementation of code that populates and reads organizational records from ENS.
We will be holding regular meetings on Thursdays at 10am ET (3pm GMT) as listed on our Luma page. Our expected schedule is as follows:
- September 25, 2025: Chat with Ori from Mechanism Institute on strategy for community adoption
- October 9, 2025: Spec iteration and feedback
- October 23, 2025: Spec iteration and feedback
- November 6, 2025: Spec iteration and feedback
- November 20, 2025: PoC iteration and feedback
- December 4, 2025: PoC iteration and feedback
- December 18, 2025: Community roadshow
To get involved, please join our Telegram group!