Summary
This proposal recommends adopting the Squid SDK as the foundation indexing framework for ENSNode V2 to address scalability, cost efficiency, and long-term flexibility challenges. SQD’s modular architecture is purpose-built to handle the multichain and high-throughput demands of ENS as it evolves as an ecosystem.
Key benefits include:
- 20-30x+ faster sync speeds on data lake-enabled chains vs Ponder (20 minutes to index Uniswap V3 USDC / ETH swaps vs 9 hours with Ponder + Alchemy RPC - “Pay As You Go” 10,000 CU/s plan).
- Multiple data sink options - PostgreSQL, file stores (CSV, Parquet), and BigQuery - enabling developers to choose the right storage backend for their specific requirements.
- Decentralized data distribution (via ~3000 independent worker nodes) and decentralized access portals.
- 200+ supported networks across EVM, zkEVM, Substrate, Solana, and other VMs.
- Zero vendor lock-in through open-source, self-hostable actively maintained modular architecture.
- Established ecosystem - hundreds of projects already index with the Squid SDK across multiple VMs, driving ~0.40 billion on‑chain queries in the last 90 days (~4.9 million/day — https://network.subsquid.io/)
Architecture Overview
At its core, SQD maintains a data lake of ~2.4PB of historic data across 200+ chains. This data is distributed in a decentralized way via a peer-to-peer network of ~3,000 workers who contribute their storage and compute to the network. This network can be easily accessed via the Gateways or decentralized Portals. Portals are either hosted by a third party or self-hosted. Portals can completely replace RPCs and include a built-in caching layer for real time on-chain data (via Hot Blocks).
Indexers—whether maintained by SQD or third parties (even Subgraphs via an adapter)—can access the data lake via Portals if the data lake ingestion is supported. There are currently multiple indexers utilizing the SQD Network (including those by SQD and third parties). Building within the SQD ecosystem means your indexer can easily be distributed to our institutional partners via OceanStream and integrated into future SQD or third party data distribution products.
Our most versatile indexing solution is the Squid SDK. It combines data from the data lake for historic data ingestion and processing with RPC for real-time data processing (can be used with just RPC as well). It is a very modular toolkit which lets you swap out and combine processors with a selection of data sinks/databases, as well as the data access layer, such as GraphQL (which is also optional but important for Subgraph feature parity).
The Squid SDK is optimized to handle large streams of data from the data lake. A typical stream is processed at roughly 5-10k blocks/sec (with writes). To store this data efficiently, the Squid SDK uses batch block handlers. This means all blocks and their data are processed in batches and inserted into the database as single transactions (but traditional event handlers can be used, although less performant in advanced cases). A single squid can index multiple chains in parallel and write to one database.
Every layer of the network is decoupled and modularized. The open and expandable nature of the Squid SDK ensures it can cover a wide range of use cases without having to fight against the framework.
Scaling Namechain & Sub-Name Expansion
Namechain will fundamentally change the way ENS handles data:
While approximately 1.6 million .eth root names exist on Ethereum mainnet, the broader ENS ecosystem has expanded dramatically through sub-names—15-16 million now live on L2s or off-chain resolvers, representing roughly 90% of the entire ENS namespace:
- cb.id alone contributes about 15 million off-chain usernames and continues growing rapidly
- Base “Basenames” has surpassed 1 million minted sub-names
- Linea hosts approximately 500,000 on-chain sub-names
- Additional networks like Optimism and Arbitrum contribute the remainder
The architecture faces the following challenge: for every write operation, there are thousands of downstream reads from wallets, dApps, UIs and backends. To meet Namechain’s demands ENS’s indexing infrastructure must:
- Synchronize millions of records across L1, multiple L2s, and off-chain stores with minimal latency.
- Optimize for read retrieval - Must have an extensible and flexible database layer to support increasing read heavy demands.
- Provide first-class off-chain data support - Seamlessly integrate off-chain resolvers and data sources with on-chain records, enabling unified queries across hybrid on-chain/off-chain namespaces without compromising performance or developer experience.
Comparative Analysis - Ponder vs the Squid SDK
| Criteria | Ponder | Squid SDK |
|---|---|---|
| SDK | TypeScript-first, event handler based | TypeScript-first, batch block handler based (easily add your own event handlers) |
| Limited by PostgreSQL-only pipeline | Modular data sinks (PostgreSQL, BigQuery, CSV, Parquet, more in the works) | |
| Sync Speed | ~15x faster than The Graph | ~20-30x faster than Ponder on data lake-enabled chains |
| Cost Efficiency | High RPC costs for the cold start index | Currently free data ingestion from the data lake (Once the SQD network monetization mechanism is in place, the projected cost will be charged per gigabyte of raw on-chain data). Same RPC costs w/ the SQD network |
| Multichain Support | EVM-only | 200+ networks (EVM, Substrate, Solana, Fuel) |
| Reindexing Flexibility / Cache | Indexer-level cache | Block cache is decoupled from indexer via the Portal / Hot Blocks (subject to the database performance) |
| Off chain data access | Off‑chain HTTP/IPFS calls are only allowed in code that runs outside the indexing handlers. Indexing functions cannot call HTTP/IPFS or touch off‑chain tables. (deterministic by construction) | Call APIs during or outside of the indexing loop, either inside every processor.run() batch with no read / write limitations (use fetch, axios, etc / access IPFS gateways, S3, etc) or outside of it. (deterministic by convention) |
Key Distinctions
The three key distinctions between Ponder and the Squid SDK are performance, decentralization, and data processing philosophies - strict boundaries with limited control versus complete developer freedom (offering freedom, not imposing obligations).
Real-world usage demonstrates that extendability and modularity consistently outperform constrained approaches in scalability-first indexing workflows. This makes scaling easier by embracing flexibility rather than fighting the limitations imposed by restrictive SDK rules.
Performance Metrics
1. Reindexing Cost Reduction
- Current (Uniswap V3): ~$90 per archive reindex, $9.00 at the tier‑one rate of $0.45 per M CU / 1M blocks (using Alchemy’s pricing) (real world tests show roughly 5.7m requests used totalling around $57).
- With SQD: once token‑metered billing is live, ingestion will be charged per raw‑data GiB (exact rate TBA), while real‑time RPC overhead remains unchanged.
2. Performance Benchmark
Methodology:
For this benchmark, we synced all USDC/WETH Uniswap V3 swaps on Ethereum Mainnet from block 12,376,729 to 22,797,000, a range of approximately 10 million blocks. This resulted in a total of 9,159,057 swap entities. The tests were conducted sequentially on a dedicated server.
We added the server’s local time to the entities at the time of each event write. We then used SQL to aggregate the records per minute, calculate the average, and export the data to a CSV file for analysis.
Two runs were performed from different servers, both covering the same data range. The results from the first run were selected for this proposal.
The code for this benchmark is publicly available for reproduction, and further benchmarks can be created upon request.
Results:
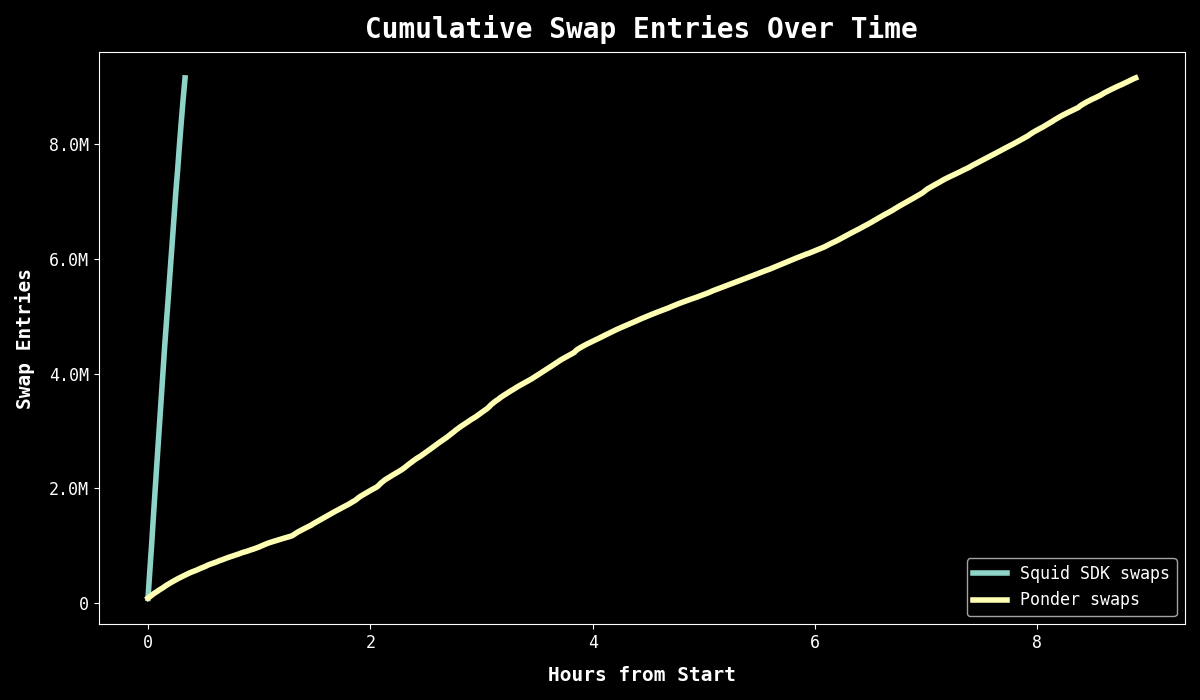
| Indexer | Total Sync Time Hrs (trunc) | Avg Blocks/sec | Avg Events/sec | Cost | Speed‑up vs. Ponder (SQD/Ponder) |
|---|---|---|---|---|---|
| Ponder | 08:53:00 | 325 blocks/sec | 286.40 events/sec | ~$57 | Baseline 1x |
| Squid SDK | 00:20:00 | 8,683 blocks/sec | 7,632 blocks/sec | $0* (no RPC) | ~26.65x faster than baseline |
Important note: Ponder’s speed is limited by a commercial RPC throughput. Alchemy offered the fastest rate, the enterprise plan might offer a better performance but it is not accessible for the majority of the developers.
Migration Proposal
After conducting a thorough analysis of the ENS Node repository, I can confirm feature parity with the ENS Subgraph and the newly integrated Ponder logic. We can create a fork and execute a partial migration of the Ponder code to the Squid SDK. Additionally, we can produce performance benchmarks for the core development team to run and compare both performance metrics and developer experience. During the performance and reliability test we can perform a full migration in the background.
Depending on release requirements, we can complete a full migration within 1-2 months (or sooner if necessary), utilizing our core team resources. We already serve multiple clients with similar data requirements to ENS, including those currently operating on Linea. We can provide first-class support to the ENS protocol and ecosystem, while also reaching a broader range of data consumers on behalf of ENS at both institutional and DeFi data pipeline levels.
We would like to establish a close partnership with ENS, assisting the protocol with upgrades to new SDK versions, providing technical support, and helping with scaling initiatives. Additionally, we maintain an active network of builders who can be deployed to add features at the indexing level should additional assistance be required.
Upon the release of Namechain, it will be added to the decentralized network for fast ingestion, allowing builders to create powerful, data-rich multi-chain experiences by enabling them to select the archive source for Namechain data without having to worry about optimizing indexing performance. Lastly, ENS will have a direct stake in the SQD’s decentralised‑development roadmap and in shaping the Squid SDK itself, ensuring both evolve to meet ENS’s long‑term performance and user‑experience goals.
Final Thoughts
The Squid SDK provides a future-proof and mature indexing solution that aligns with ENS’s multichain ambitions and long-term scalability objectives. The combination of cost savings, enhanced performance, and architectural flexibility makes it the optimal choice for ENS’s next-generation indexing requirements.
SQD’s extensive experience from pushing the boundaries of indexing on the most rapid chains enables stress-free scaling of Namechain and future developments. Trusted by hundreds of protocols including GMX, PancakeSwap, Shibarium, Railgun and Decentraland, SQD is committed to the decentralization and modularity of the Squid SDK.
The protocol is under active development, with ongoing improvements in performance, decentralization and SDK experience. We are positioned to help ENS achieve its goals without requiring future migrations due to scalability constraints.