Validity depends on context. Within an English-speaking context, aрe.eth should be flagged, but within a Russian-speaking context, something like овечкин8.eth shouldn’t be flagged. Since they both contain ASCII+Cryllic, I don’t think a simple yes/no validity boolean is enough to capture this distinction.
I don’t think we should dictate what combinations of character sets are or aren’t valid. Instead, we should provide an easy way for ecosystem developers to know what’s actually inside an input domain, and provide simple building blocks to construct custom validity rules/guidelines. I believe the (uint256 charsets) return value provides this.
Taking your example, the English-speaking ecosystem developer would only need to write valid = (charset == ASCII) to flag aрe.eth as invalid.
I just wanted to check in and see if on-chain normalization is being worked on, or if there are any status updates as the last reply to this thread was in July.
I wrote a Solidity Unicode NF implementation so we have all of the parts necessary.
I just need to integrate it into the previous contract and upload the payloads according to the latest spec and we should be 100% match.
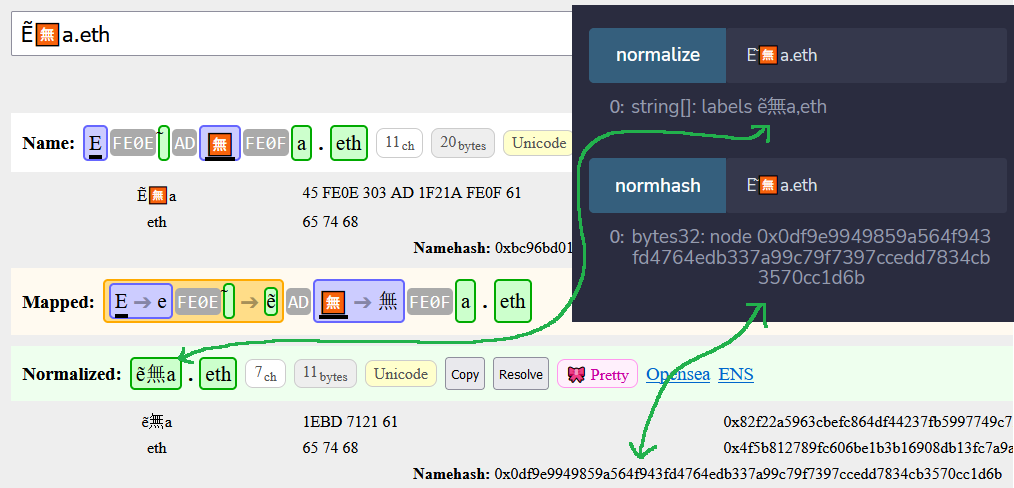
Edit: This is really hacky and untested but appears to work just by gluing some pieces together. It follows the latest ENSIP rules. It has underscore, label extension (double hyphen), and combining mark (leading, emoji, adjacent) logic. Beautifier works too (missing the regional indicator separator logic.) https://rinkeby.etherscan.io/address/0x1E321B0fdbbc022D959F5D9eB829f071cC375131#readContract
normalize() gives array of labels (unfortunately if you copy from etherscan periods will be commas)
normhash() goes straight from unnormalized to namehash