Way back in December, I made the following comment in our now infamous ENS Name Normalization thread:
After taking some time to look into it, I believe that an onchain implementation of “ENS Name Normalization” (as proposed by @raffy in Draft ENSIP - Standardization of ENS Name Normalization) is both technically feasible and financially economic within a mainnet contract.
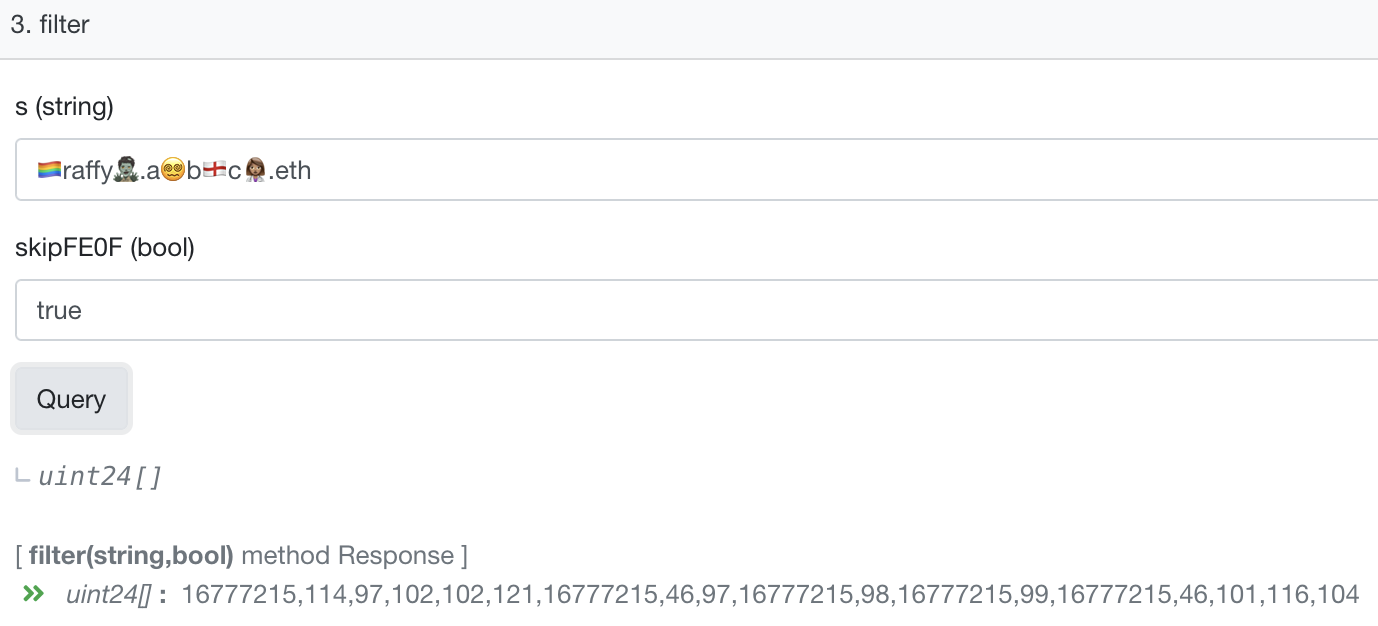
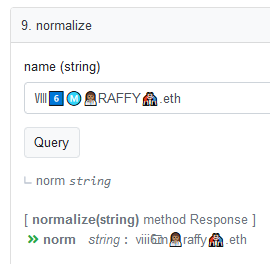
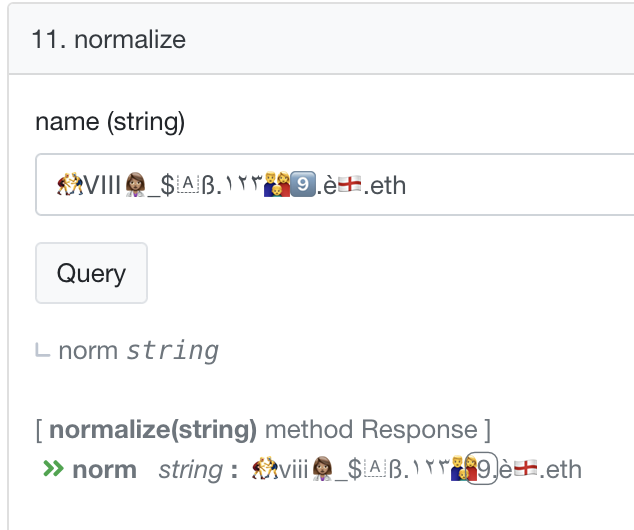
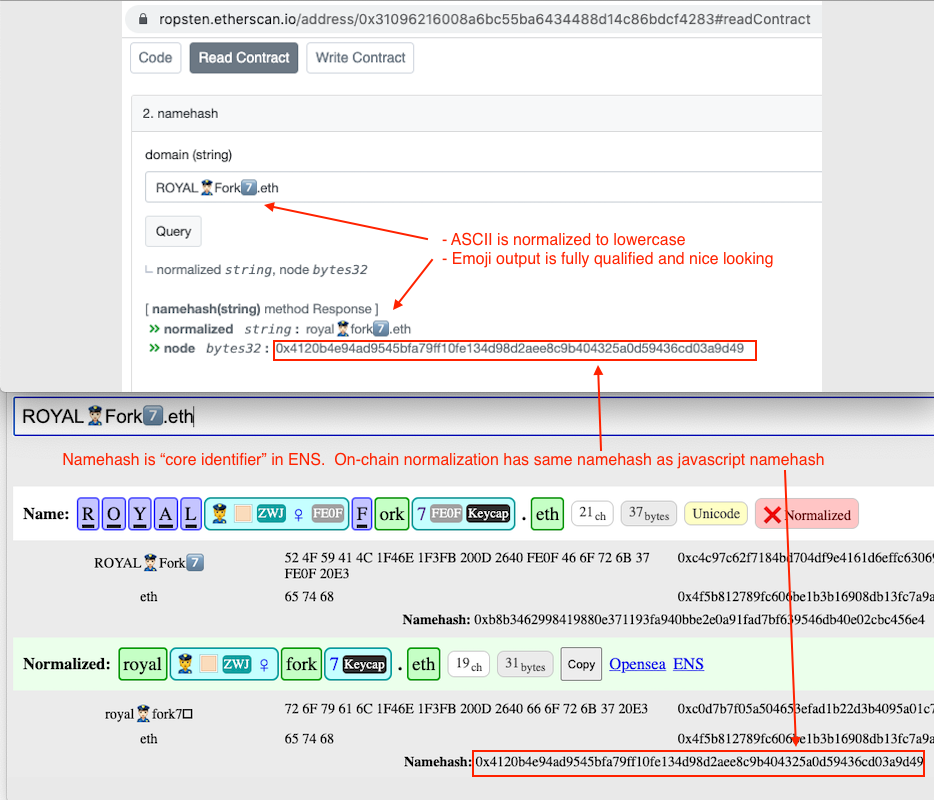
As a small proof of concept, I built github.com/royalfork/ens-ascii-normalizer, which you can try out on etherscan. ENSNormalizeAscii contains the following functions:
namehash(string domain) returns (string, bytes32)returns the normalized domain, and the namehash node of the normalized domain (reverting if domain is invalid).owner(string domain) returns (address)uses namehash to return the domain’s current ENS owner.
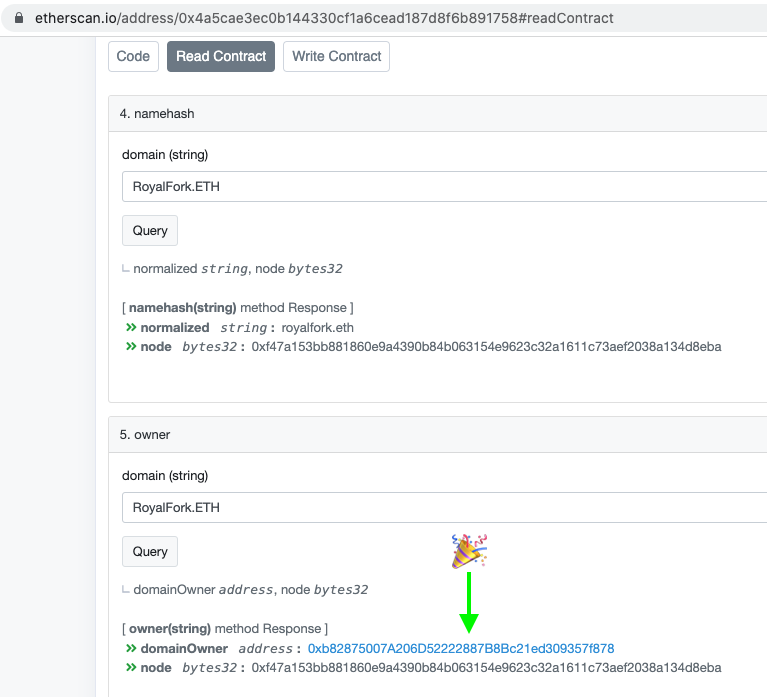
Note: This contract only supports ASCII-only domains. If a domain contains non-ASCII characters, namehash/lookup will revert.
Moving to full unicode support:
- utf8 encoding/decoding incurs additional complexity and computing cost over just ASCII domains. In preliminary tests, validation of a simple 6 letter unicode domain cost about 200000 gas (~$5), which is probably too expensive to be called by other contracts (although this number is based on unoptimized solidity code, and could be reduced).
- IDNA2008 has ~1 million “unicode” rules which would all need to be supported. These rule can be compressed (run length encoding) into a set of ~2000 “rule import” eth transactions, each costing ~1,500,000 gas. This puts the total cost of IDNA2008 rule importation at around $85,000 (at 30 gwei gas).
- Emoji validation requires importation of another ~3000 rules (based on saving the full RGI set on-chain, but it might be possible to do this with less). Not sure on the best data structures for this part yet, but would estimate that emoji validation data import would cost another $20,000-$50,000 in gas (I can try and firm up a better estimate if needed).
- Most UTS-46 mapping would be encoded into the IDNA2008 rule set, but “1 char → n char” mappings would require separate importation. There are only a few of these, but this could add another ~$10,000 to deployment costs (also, implementing unicode 1->n mappings isn’t as simple as the ascii 1->1 mappings, some inline assembly is required to make those mappings memory efficient).
- Once on-chain, the rules would be customizable, so an “owner” could allow/disallow certain characters and/or change how context-based validation works (emoji validation is implemented via context-based validation).
Not sure if ENSAsciiNormalizer is the first mainnet “string → owner” contract for ENS, but I find it nice to perform direct on-chain domain lookup/validation without the need for intermediary client-side code (it’s also nice to check for ZWJ characters directly on etherscan). If there’s any interest in a “full unicode normalization” contract (and we can collectively stomach the ~$200,000 in fees it would take us to get there), I can put together a more detailed RFP. Would be pretty cool to implement something like this, and it could vastly simplify 3rd party integrations (instead of asking etherscan, metamask, opensea, ethers.js, everyone else to “update their code” everytime ENS normalization rules are updated, we can just point them to our easy-to-use on-chain normalization function and be done with it).
 and
and  to the emoji allowlist…all other emoji will revert if you try and namehash, because they aren’t in the allowlist.
to the emoji allowlist…all other emoji will revert if you try and namehash, because they aren’t in the allowlist.