I reverted the demo to what I think should be standardized and computed another error report.
- UTS-51 Emoji parsing happens first. It does all RGI sequences. It also includes the non-RGI whitelist. Any emoji that was mangled by IDNA 2003 is removed. In all cases
FE0Fis dropped.FE0Eends emoji parsing. - UTS-46 using IDNA 2003, STD3, deviations are valid. No CheckHyphens. No punycode. No combining mark restrictions. No ContextO. No CheckBidi. No script restrictions. No confusables.
$and_are allowed. The alternative stops (3002 FF0E FF61) are disabled. ZWJ and ZWNJ outside of emoji are disabled.
I am updating my ENSIP to describe the process above.
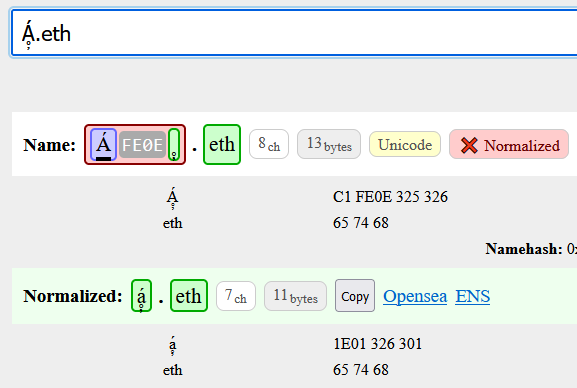
I added a new feature to the demo which indicates that a block of text requires NFC. The following example is a mapped character, an ignored character, and a valid character, that when merged together (where the ignored character is removed) gets rearranged: C1 FE0F 325 326 → 10E1 326 301.
This algorithm is simple enough that it can be implemented on-chain and it’s development isn’t blocked by the fine details of confusables.
@royalfork is developing an string → string implementation. I am currently pursuing the validation approach I described above: given a normalized name (via ens-normalize.js or an on-chain implementation) determine if is valid (trusted, reachable, not spoofed, etc. – I’m not sure what the right terminology is.)
I deployed an EmojiParser and BasicValidator (/^[a-z0-9_-.]+$/) that currently validates 94% of ENS names on-chain.
The next contract I am making is NFC quick check (uint24[] → bool) and/or NFC (uint24[] → uint24[]). With that, it should be pretty straight forward to write multiple single-script validation contracts to increase the coverage from 94% to 99%.
In terms of what is and isn’t valid, I’m still not sure. Because emoji parsing is independent of text processing (emoji can be mixed with any script, etc.), validation only needs to care about non-emoji confusables and other exotic Unicode rules. By using separate validators, we simply need to chip away at the problem.
Here are the script combinations of registered names sorted by frequency:

We could probably validate 95%+ of each script using just exemplars and double-checking for confusables.
For example, making an on-chain validator for those 70 pure Thai names is probably trivial. There are only 86 characters in the Thai script and the exemplars are even smaller. If we can agree which of those characters are confusable, the corresponding validator is only a couple lines of code.
