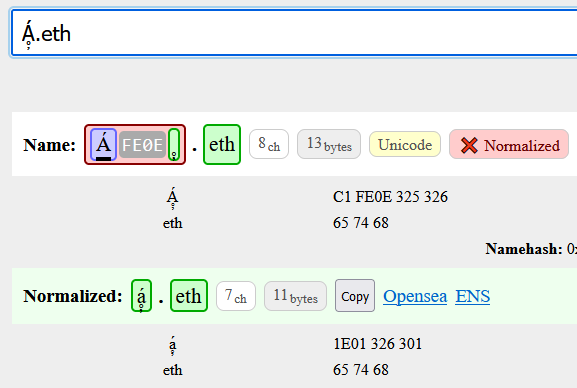
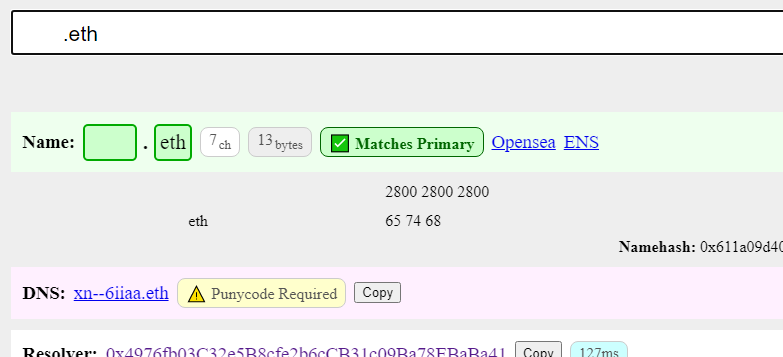
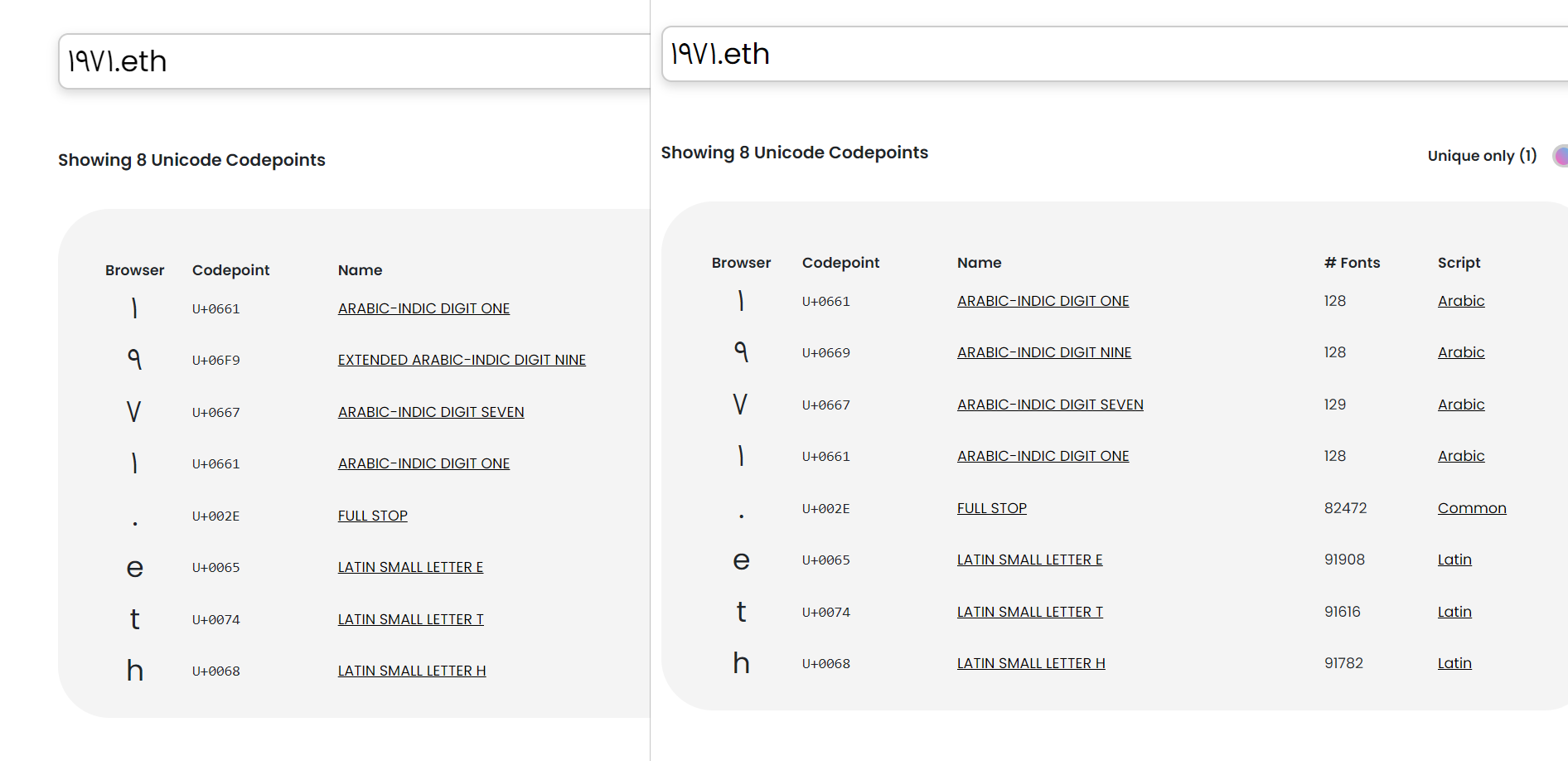
Hey, I recently registered some Indian devanagari digit names. They resolve fine currently. However, if I check them in the resolver under development at adraffy.github.io/ens-normalize.js/test/resolver.html, they give mixed results. Some digits normalize fine, while others are marked as confusable.
Here are the details for each digit:
9: 96F: Resolving
8: 96E: Not Resolving - Disallowed label “{96E}”: whole script confusing
7: 96D: Resolving
6: 96C: Resolving
5: 96B: Resolving
4: 96A: Not Resolving - Disallowed label “{96A}”: whole script confusing
3: 969: Not Resolving - Disallowed label “{969}”: whole script confusing
2: 968: Not Resolving - Disallowed label “{968}”: whole script confusing
1: 967: Not Resolving - Disallowed label “{967}”: whole script confusing
0: 966: Not Resolving - Disallowed label “{966}”: whole script confusing
Context: Devanagari is the dominant script in northen India, is used for hindi and a number of other languages, and is by far the most widely used script in India overall. Notably, Indian banknotes have both the English and the Devanagari numerals printed on them.
Would really appreciate if the team could the team provide a bit more clarity on how these confusable(s) are planned to be handled?