Alright, I’m glad that we were able find a solution for this one.
Btw, I’m a web dev and as you might have guessed my first language is Persian 
Feel free to dm me on twitter if you think I’d be able to help in some way.
2 Likes
This error report has very preliminary whole-script confusables + single-script confusables. I also updated the demo to reflect these changes.
The confusables need some adjustments but it’s better than I expected – it’s actually pretty close to my initial estimate above.
This file has the confusable groups, with their corresponding script sets.
[{"hex":"1041", "form":"၁", "uni":["Cakm","Mymr","Tale"], "ty":"C"},
{"hex":"1065", "form":"ၥ", "uni":["Mymr"], "ty":"C"}]
(2) new errors:
-
whole script confusingmeans every non-overlapping subsequence has a confusable in another script. Note: this needs relaxed to: there exists another script, that has confusables with every non-overlapping subsequence.
eg.apple(Latin) vsаррӏе(Cyrillic). -
confusing "x"means that there is a same-script confusable.
eg.avsɑ(both Latin).
Modifications to the spec:
- I made ASCII globally unconfusable.
- Each confusable group is such that if Confuse(a,b) and Confuse(b,c) then Confuse(a,c).
- For specific scripts, you can choose a default sequence, eg. Cyrillic has 3 e’s:
еꬲҽ, I madeеdefault.
Current issues:
-
You can circumvent some confusables with combining marks by inserting additional marks. eg.
Ac(A=letter, c=mark) can broken withAbc(b=another mark.) -
Many characters need their confusables disabled. eg.
٠٠٠(Arabic 000) doesn’t work at the moment because it confuses withꓸ [A4F8],١١١(Arabic 111) confuses with a bunch of things.٥۵(5 and extended-5) confuse according to the spec. -
Many confusables are missing. eg.
ѐèisn’t in the Unicode database
Overall, I think it’s doing the right thing in general, it’s just too strict.

1 Like
Great work!
Some cases I see where confusables should be disabled (as long as it’s single script, I presume):
- Arabic digits (but with the extended rules as discussed above)
- Arabic characters (e.g. مُحَمَّد)
- Persian/Farsi characters (e.g. پرسپولیس)
- Hindi characters (e.g. इंडिया)
- Hebrew characters (e.g. מבורך)
- Armenian characters (e.g. վանկազուրկ)
- Greek characters (e.g. χωρίςτράπεζα)
- Cyrillic characters (e.g. русский)
- Chinese characters (e.g. 黑客松)
- Japanese characters (e.g. ミュウツー)
- Including kanji, hiragana, katakana, and the elongation character ー
3 Likes
Can we not disable single-script confusables across the board? Presumably if two different but similar characters exist in the same script, it’s for a reason?
Sure, so ignore all same-script confusables?
Name only needs to be be single-script and cannot be whole-script confusable?
That’s what I’m suggesting - but it wasn’t a rhetorical question. Are there situations where it makes sense to prohibit a character because it’s confusable with another character in the same script?
RE whole-script confusable, how do we intend to handle these? Will we have to select a ‘canonical’ script for each pairing where this can happen?
1 Like
Even in Latin, there are many: ꭓꭕ, rꭇꭈ, iı, ꜹꜻ, ƫț, ĕě, gɡᶃƍ, etc.
Arabic: ١ (Digit 1) vs ا (Alef)
Myanmar: ၁ၥ
Some have an obvious canonical form, others it’s not clear.
I’m following the logic here + Script Extensions + Highly Restrictive + Output Confusables (they have to survive normalization: mapping + NFC).
At the moment, ASCII has priority, and everything else always conflicts. My idea above was to use a script ranking to resolve whole-script confusables to always permit one form (unless they have the same rank).
eg. if you have a name that’s covered by two scripts [A,B] and every sequence conflicts with another script [C], you consult Min(Rank(A),Rank(B)) < Rank(C) to decide if you have the “canonical” form.
1 Like
Is it reasonable to expect speakers of those languages to understand the differences? Someone who didn’t know English might ban ‘i’ because it looks a lot like ‘l’ but obviously we would find that problematic.
I’ve stayed out of this because it was generally over my head, and I don’t have a use for non-ascii characters, but…
Why perform gymnastics to accommodate edge cases? Adhering to the established allowed characters on DNS would appear to save a bunch of headaches and serve as a reliable, well-known standard for any service to easily integrate.
1 Like
The “established allowed characters on DNS” is more complex than it first appears.
DNS itself only supports a subset of ASCII - 0-9a-z_-. With punycode it supports a large part of unicode, and uses UTS-46 normalisation to handle (some degree of) disallowed or duplicative characters. Many registries impose additional limitations on top of that, such as only allowing certain scripts, or disallowing emoji.
The question becomes, what set of rules to adopt? There isn’t just one standard, and many of the existing ones have deficiencies as well.
1 Like
Hi everyone, not sure if this is 100% the right place but thought to flag one more category of alphabet, the Scandi/Nordic ones, which now seems problematic.
I minted earlier a 3letter hyphen domain (ø-ø.eth) together with other similar others, and everything was just fine until a month or so. But now, these are marked as malformed.
æ
å
ä
ö
ø
As said, these hyphenated L-L domains were totally fine for weeks, but then changed to invalid.
Would be great to know what’s happening as there’s no point extending registration if they cannot be used.
Three letter ones without hyphen, at least with just one scandi letter are still fine, eg. løv.eth
Edit:
Further to my message above, seems also that domains with two consecutive Scandi wovels are now changed to invalid. Really like my øø7.eth which has now turned useless!
Not a technical person myself but these are on common on keyboards in respective countries, some of these are also found in German and other languages, and also seem to adhere to ISO standards:
From Wikipedia: several different coding standards have existed for this alphabet:
1 Like
I’m Swedish and I can’t think of any real life use-case where you’d use Ä-Ä, Å-Å, Ö-Ö with one single letter. However, this might be an issue for people who wants to register hyphenated double-surnames.
If a Swedish surname contains an Å, Ä or Ö it shows as invalid when hyphenated with another surname. I have an Ö in one of my surnames and it’s a nightmare to use it on the internet.
PS: Å, Ä and Ö etc aren’t A and O with a mark or umlauts, in Swedish they’re their own individual letters.
1 Like
Hello frens,
So i’ve came across the keycap emojis and their visual look. Once registered the Unicode changes a bit.
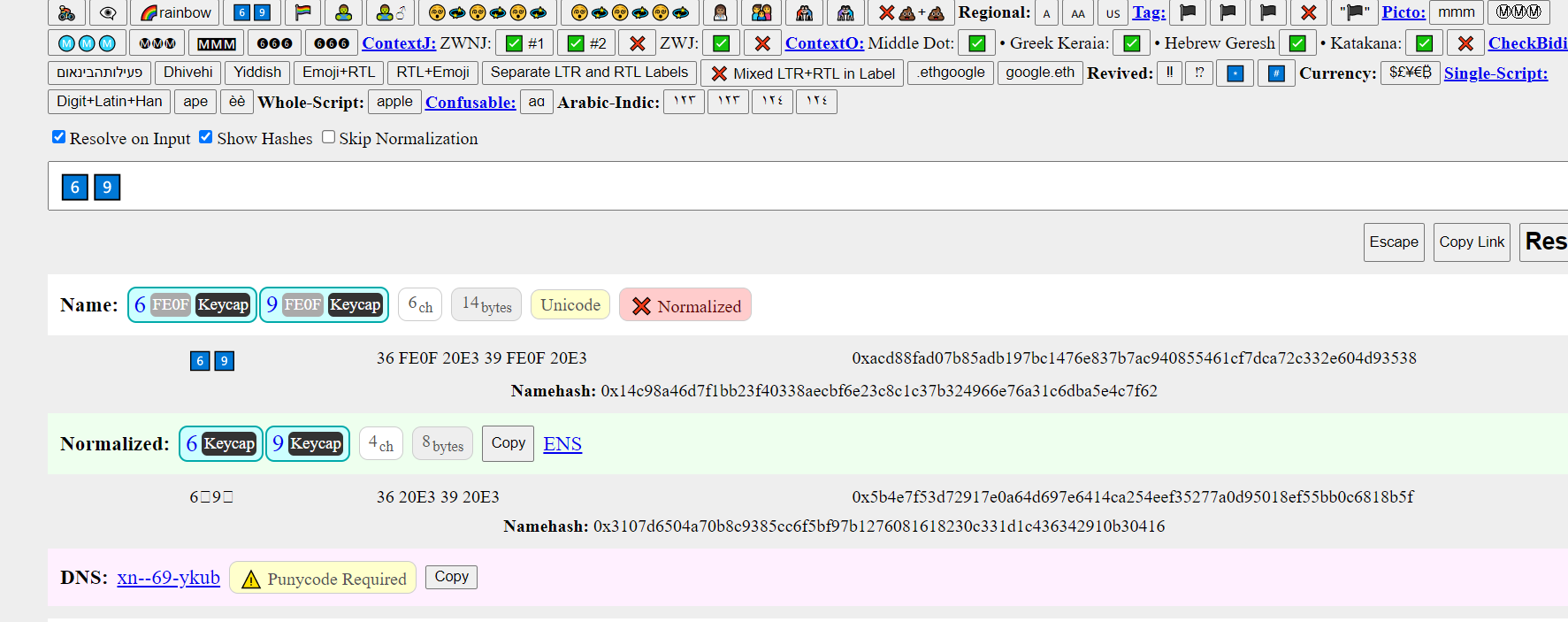
Because of this i can’t look them up on opensea nor can i search them with the original keycap emoji. Besides that, the visual look on etherscan is completely bugged out because of this. Look for yourself.
![]()
Is there a chance that you guys can get this fixed?
Kind regards,
N e
1 Like
“can’t think of any real life use-case where you’d use Ä-Ä, Å-Å, Ö-Ö with one single letter. However, this might be an issue for people who wants to register hyphenated double-surnames.”
Why people register numbers etc. that have no real meaning? They look cool, and as long as 2-letter domains are not possible the 3L ones with hyphen will be in demand.
öö - ‘night’ in Estonian
øø - short for a band called ørganics ønly, used by them on socials & spotify for example
These popped up with just a quick google by the way.
The change seems to have something to do with the combination of hyphens, and numbers with
these letters.
ööö is ok, ö-ö used to be ok but is not anymore
øøx is ok, øø7 used to be ok but is not anymore
pretty sure MØ would like hers as well, but its not possible anymore
These domains were just fine before, registered & paid for, so if they suddenly get changed to invalid, a refund is needed. And it’s also a step backward for the system.
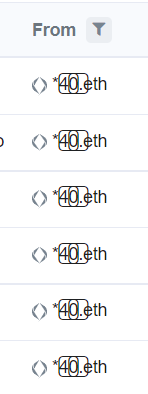
I would love to see Keycap Digits  normalized and show up as proper visual emojis on Opensea and ENS as well. Seems like a simple addition. With all the interest in numbers I would think this would be pretty cool to correct the visualization.
normalized and show up as proper visual emojis on Opensea and ENS as well. Seems like a simple addition. With all the interest in numbers I would think this would be pretty cool to correct the visualization.
2 Likes
Would be a visual superior and amazing ENS address. 
 .eth for example would look absolutely stunning.
.eth for example would look absolutely stunning.
1 Like
Since keycap names have already been registered, keycaps display can only be fixed with a beautifier-like function during display. The purpose of this function would be to insert FE0F into keycap and emoji sequences for proper presentation. While this function is trivial to implement, the issue would be getting platforms and applications to use it.
Your registered name is likely fine. It is my fault for dragging the ball on finishing the normalization standardization proposal. There isn’t a clear standard yet so different apps are stuck using their own method to determine if a name is “valid”.
3 Likes
That beautifier function would fix it all. Would be amazing if this could get implemented.
I haven’t been able to establish an algorithm worth standardizing that incorporates all of the validation checks, that prevents all known spoofs, and has a reasonable on-chain implementation.
My plan is to revert to my January release which fixes the Emoji and ZWJ issue and establishes the mechanical process of preparing a name for hashing. I will update my ENSIP to match. This should be done soon.
I also think it’s wise to use IDNA 2003 + whatever characters we discussed (underscore, +missing keycaps, +missing emoji, currency symbols) and remove ContextO, CheckBidi, CheckHyphens, etc. If there are any other characters worth enabling, please let me know.
A separate library (that won’t be part of the ENSIP) will be provided to apply validation checks. However, I think on-chain solutions might better.
For an on-chain implementation, I think the first step is writing a function that asserts if a name was normalized correctly: string → bool
I would consider names that match /^[a-z0-9_-.]+$/ w/Emoji as the “safest” set of ENS names (ignoring skin color emoji differences.) 94% of registered names fit this criteria.
My thinking is emoji parsing is independent of text parsing. We just need a function that takes a string abcXzYdef (where “abc” and “def” are text and XzY is an emoji ZWJ sequence) and produces a new string abcEEEdef, where E acts like a generic emoji placeholder. Then a second pass is made using a text filter.
UTF8.decode(string) -> uint24[] // revert if invalid
Emoji.filter(uint24[]) -> uint24[] // revert if middle of sequence
BasicValidator.validate(uint24[]) // revert if invalid codepoint
I’ve written two versions of the emoji filter contract. One works as a library and uses a state machine, it’s about 160K gas to validate 💩raffy🏳🌈.eth, the other is a contract that uses storage, and is about 60K gas.
2 Likes
Brainstorming: This might be stupid but what if we assert and store on-chain that a name is valid? The equivalent of a “blue” checkmark?
Imagine a master contract, with the following pseudocode:
interface IValidator {
function validate(uint24[] cps);
}
mapping (uint256 => address) validated;
mapping (address => uint256) ranks;
address[] validators;
address emoji;
function setEmojiFilter(address) onlyDAO; // upgradable emoji
function setValidator(address, uint256 rank) onlyDAO; // set 0 to invalidate
function hasEmoji(string name) returns (bool);
function getValidatorRank(address) returns (uint256);
function getNameRank(string name) returns (uint256);
function getNodeRank(uint256 node) returns (uint256);
function getBatchRank(string[] names) returns (uint256[]);
// return true if name is validated by validator
// return false is name is already validated by a better validator
// revert if name is invalid
function validate(address validator, string name, bool hasEmoji) returns (bool) {
uint256 rank = getValidatorRank(validator);
require(rank > 0, "not a validator");
uint256 node = namehash(name);
address validator0 = validated[node];
if (validator0 != address(0x0)) { // prior validation exists
uint256 rank0 = getValidatorRank(validator0);
if (rank0 > 0 && rank0 <= rank) return false; // prior rank is better
}
uint24[] cps = UTF8.decode(name);
if (hasEmoji) cps = Emoji(emoji).filter(cps);
IValidator(validator).validate(cps);
validated[node] = validator;
return true; // valid
}
function willValidate(address validator, string name, bool hasEmoji) view {
uint256 rank = getValidatorRank(validator);
require(rank > 0, "not a validator");
uint24[] cps = UTF8.decode(name);
if (hasEmoji) cps = Emoji(emoji).filter(cps);
IValidator(validator).validate(cps);
}
To check if a name is valid: getNameRank("raffy.eth") > 0
To validate a name (this could be one-button on a website or part of the registration/renew process):
- You normalize your name.
- You eth_call
hasEmojito see if your name has emoji. - You eth_call
validators()to get a list of validator contracts. - You loop through the validators and find the most efficient one/best rank that
willValidate() - You submit a tx for
validate()with that contract, if your name has emoji, and the name. On success, it associates the node of the name with the address of contract that validated it.
Validations never expire. However, the underlying validator can get revoked by the master contract. Anyone can validate any name. Validator ranking can be used for filtering/trust and preventing someone from “downgrading” a strongly-validated name to more complex validator.
Validator ranking can also be used client-side: simply error if the name isn’t validated or if it has a rank above some threshold. Ranks could be associated with a color.
0 = Invalid
100 = Basic /^[a-z0-9-_]+/
200 = Valid ASCII
200 = Just Arab Digits
300 = Latin (single-script)
300 = Greek (single-script, no overlapping confusables)
Validators only need to implement codepoint validation on non-emoji output characters.
Validators only need to validate a subset of the valid name space.
A separate contract will be needed to efficiently perform NFC QuickCheck (to ensure a name is in NFC) for complex charsets.
The DAO could vote to approve new validation contracts. Each language could have a separate/multiple validator contracts. You could even have a non-algorithmic validator contract that simply has an append-only list of approved names. The ranks of each validator can be adjusted by the DAO if a problem is found.
If the ENS registrar was provided a hint of what validator to use (possibly through the commitment), it could call validate during registration.
2 Likes