hello, would you be added russian alphabets as ens?
will i get a refund for my ENS ape.eth since its invalid on OS and it got unlisted.
due, ape the cyrillic “p” mention as malicious/scam name, when i bought from ENS it did not mention anything regarding malicious/scam.
so please i would like to be refunded 707$ for the name i bought and has no use of it.
Or i wish this to be resolved and be listed on OS
thank you
Can you provide a justification for registering the name other than trying to trick people into thinking it’s ‘ape.eth’?
Buying ape.eth with cyrillic “p” was not for tricking people because i wanted to use that for myself as its my first short ens name it looked nice, i knew that the name will have caution  as most people have same names but sometimes with caution sign or sometimes with replacing emoji’s or l,1
as most people have same names but sometimes with caution sign or sometimes with replacing emoji’s or l,1
I know that purchasing the name will have my name with caution
But my ens being Delisted in OS and not showing in my wallet and being surprised by developers saying that my name ape.eth is a malicious/scam without informing me or anything mentioned about scam before i paid 707$ for 3 letters name which i like… its not good. My intentions was not to scam, i just wanted to have a nice 3 letters name thats all.
i wish next time if you inform and mention to the people who are registering a name with cyrillic word to know that this might happen.
AThats why now im shocked and i feel sad that i lost 707$ for nothing.
Please i wish my money to be refunded @nick.eth
Hello any update please
Please wait until these normalization changes are finalized. Once we have the final code and reports, we’ll know exactly which previously-valid names will have invalid metadata, and the ENS community here will I’m sure have a discussion about how to handle these names and under what circumstances refunds may be given, etc.
See these objectives laid out by Nick earlier in the thread: ENS Name Normalization - #20 by nick.eth
1 Like
Please keep conversation on this topic to discussion of the changes to the normalisation function. Offtopic replies such as requests for refunds or queries about the status of individual names will be deleted.
lots of normalization problems with arabic numerals it seems -
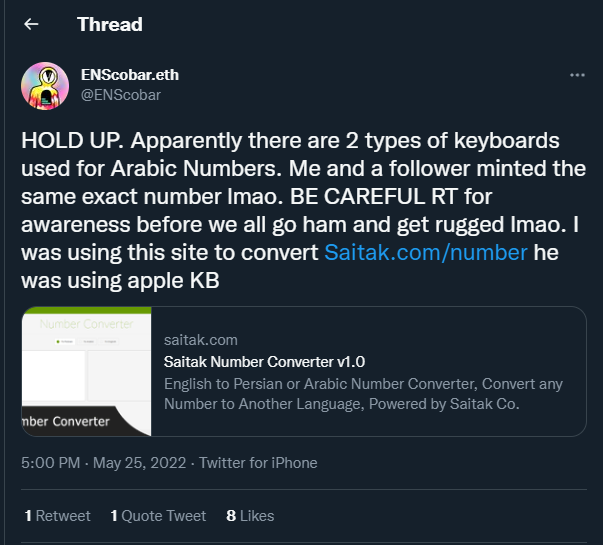
https://opensea.io/assets/ethereum/0x57f1887a8bf19b14fc0df6fd9b2acc9af147ea85/57878234801101706464907200301382902911825934948133920256067941549956179541975
https://opensea.io/assets/ethereum/0x57f1887a8bf19b14fc0df6fd9b2acc9af147ea85/85813848692050262483492322019064772227096889665505083244435923863898171704685
two visually identical domains, the normalization checker tool reports one as normalized the other one as not normalized
https://opensea.io/assets/ethereum/0x57f1887a8bf19b14fc0df6fd9b2acc9af147ea85/99942910256347406037411455050680494180435446940151882100227360960046000673397
https://opensea.io/assets/ethereum/0x57f1887a8bf19b14fc0df6fd9b2acc9af147ea85/41056161334239367631533052882077582946209860478205435780213207492284282125669
again two visually identical domains, the tool reports both are normalized
Hey! 
Recently people have taken to registering Arabic-Indic digits, like ٠٠١.eth.
However, as you are probably already aware, there are separate “extended” versions of those digits for whatever reason.
- Arabic-Indic Digit Zero: https://www.compart.com/en/unicode/U+0660
- Extended Arabic-Indic Digit Zero https://www.compart.com/en/unicode/U+06F0
Both show as valid right now in the live demo, but I’m assuming that’s just because you haven’t finalized/enabled the confusables code right?
(Incidentally, both sets of digits can be registered right now through the ENS manager app)
Is the plan for those characters to normalize the “extended” ones to the regular ones? Like ۰۰۱.eth would normalize to ٠٠١.eth?
Or will the extended digits just become invalid altogether?
Thanks!
2 Likes
it seems that indian numerals resolve to english numerals on opensea. is this a problem with opensea, or something ENS can change?
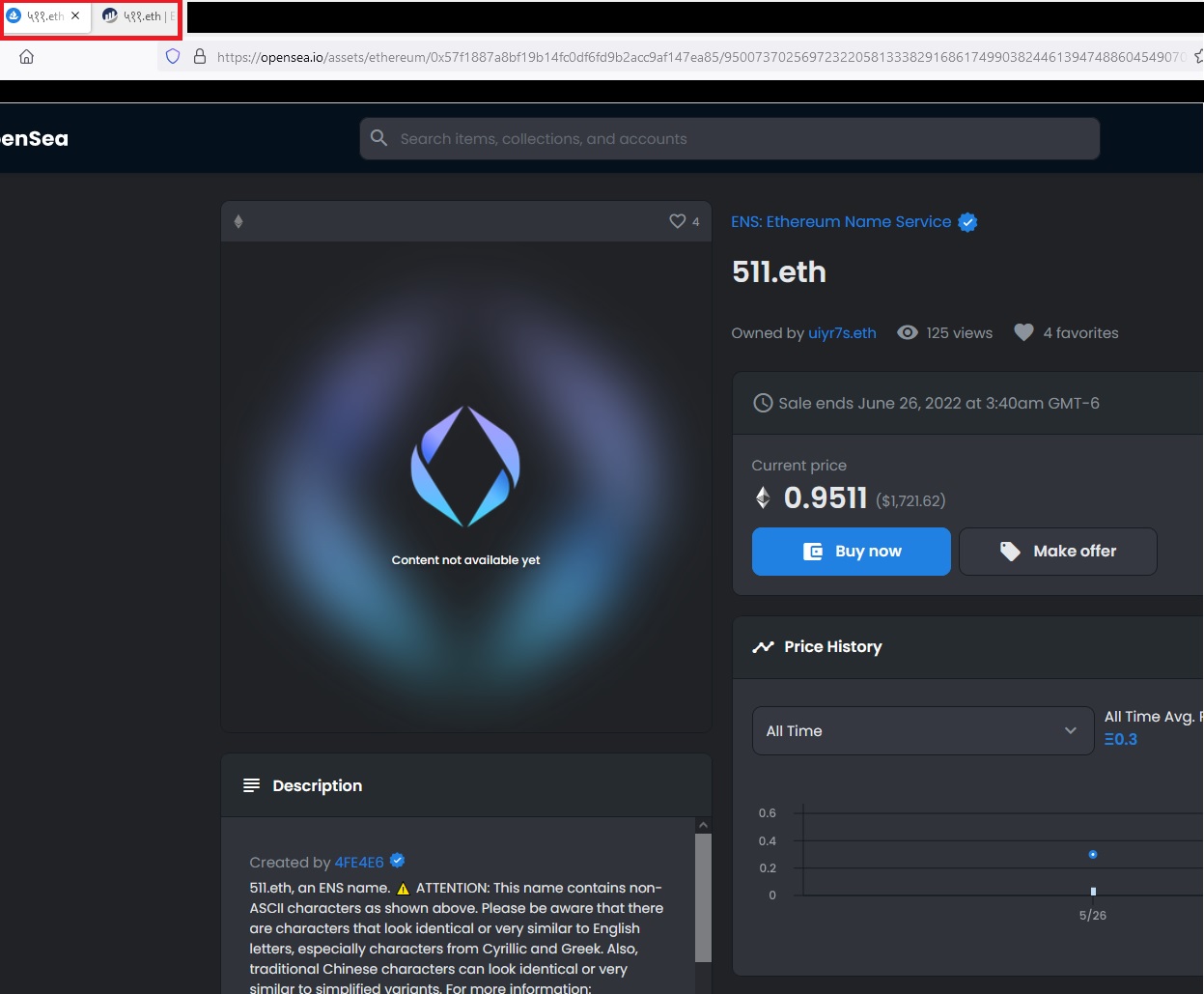
the domain in question - https://opensea.io/assets/ethereum/0x57f1887a8bf19b14fc0df6fd9b2acc9af147ea85/9500737025697232205813338291686174990382446139474886045490700210042399989925
there are of course many more examples
This looks to be something specific to how OS is resolving it, not having to do with current ENS name normalization. On LooksRare the same name does not “convert” to English numerals.
Oddly enough, OS has the right ENS name in the window tab’s title:
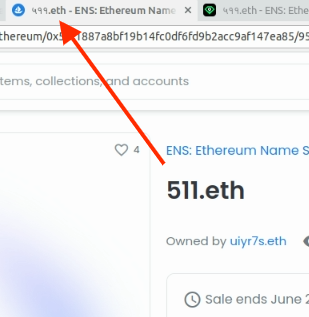
Names with special characters will still show the non-ascii warning. This warning is returned from the ENS metadata service: GitHub - ensdomains/ens-metadata-service
There’s another thread about recent metadata issues specific to OpenSea. It’s here: OpenSea "content not available yet" and missing ENS names
1 Like
Arabic script ens domains have been hot lately and seem to have some character resolution issues
The Extended Arabic-Indic digits are Persian digits used for Persian keyboards. They look similar to Arabic, except for the digits 4, 5 and 6.
So invalidating them won’t make sense.
But there is one thing ENS could do. Mixing the two unicode scripts should not be allowed during registration.
Here is an example:
https://adraffy.github.io/ens-normalize.js/test/resolver.html#٠٧۷
In @randomname’s comment above the first ENS has Persian zeros prepended to Arabic digit 6.
The other examples are either Arabic or Persian, and there is nothing wrong with them.
2 Likes
Sorry I’ve been a little slow on updates.
What Octexor said is correct, however there is a whole-script confusable issue with Arabic digits. In my latest code (not yet released), you can’t have a name fully composed of [0-3,7-9] because all those digits exist in multiple separate scripts as confusables.
To permit 123.eth, I suggest we map one set of [0-3,7-9] digits to the other, and allow the mapped version in the appropriate scripts. This would also allow (2) versions of 124.eth: ١٢٤ and ١٢۴.
Otherwise, the only Arabic pure digit names that are allowed would be ones that contain one or more 4-6 (which determines the script.)
Edit: The problem with mapping is that we have to choose one of the scripts.
3 Likes
I see the confusion caused by these sets of digits.
And it’s hard to make these decisions for a whole community of users in the middle east with different languages.
But, at least in the case of Persian and Arabic (There are also Urdu, Sindhi and Kurdish which are similar) I can see that many of the Unicode characters used for the alphabets of these languages are the same. (Arabic characters are borrowed for the Persian keyboard and extended) And I’m wondering why these two sets of numbers exist where 7 of the 10 glyphs are exactly the same. (۰ ۱ ۲ ۳ ۷ ۸ ۹)
Considering the history of these languages and the fact that currently less of the [U+06F0 - U+06F9] digits are used in the registered names, I think the easiest option would be to map
[U+06F0 - U+06F3, U+06F7 - U+06F9] to [U+0660 - U+0663, U+0667 - U+0669]
And permit mixing the 6 other characters (۴ ٤ ۵ ٥ ۶ ٦) as @raffy described.
I was worried about name lookups, (that some of the Persian digits would not be found even though they were entered during registration) but I guess the same normalization has to be done for every name lookup anyways, because of all the other mappings.
The sooner the new normalization is released, the less confusions will happen during mass adoption.
More details about Unicode for middle eastern languages can be found here:
Another interesting topic to consider for normalization is the use of diacritics in these languages which can result in different permutations of each word. I recommend to consult with native speakers of each language for that.
@raffy thanks for the awesome work you are doing. I have no idea how you are able to wrap you head around all the possible languages and their glyphs!
3 Likes
I was always under the assumption that Arabic-Indic Digit Zero were the valid original ones, and the extended Arabic ones were the invalid ones, trying to copy.
@raffy
I’m not exactly understanding the proposed outcome. What do you mean you can’t have a name fully composed of 0-3 for example, so you cannot have 003 in Arabic but you can have 004? So to have 123.eth , the non extended should be the original and the extended version should have a yellow traiangle or be considered a duplicate or not allowed?
I think everyone was under the impression that the Arabic-Indic Digit Zero were the original and authentic, and the extended version is technically invalid and is a duplicate with yellow caution sign?
I’m not sure how we resolve the issue, but:
-
١٢٣ [661 662 663]and۱۲۳ [6F1 6F2 6F3]look the same (123 vs 123). -
١٢٤ [661 662 664]and۱۲۴ [6F1 6F2 6F4]look different (124 vs 124). -
۱۲٤ [661 662 664]and۱۲٤ [6F1 6F2 664]look the same (124 vs 124).
If the name is pure digits, then it needs one digit from 4-6 (case 2) + the non-extended/extended exclusion rule (where second example of case 3 fails) to be valid.
If we want to support pure digit names with strictly 0-3,7-9 digits (case 1), we have to pick one. Otherwise, how do you justify case 1 and case 3 being two separate names?
1 Like
Yeah it seems like for [0-3,7-9] the “Extended” digits should map to the regular digits. And then [4-6] can be allowed from both sets since they are distinct.
@474.ETH so if that mapping is used, then yes you can have 003 in Arabic, the valid name would use the non-extended digits: ٠٠٣.eth
Any use of the extended [0-3,7-9] digits would just normalize to the regular digits. So if someone enters the extended ۰۰۳.eth, it would normalize to the non-extended ٠٠٣.eth, and would resolve records for that non-extended name against the smart contracts.
Even if you did have the extended ۰۰۳.eth registered, it would have invalid metadata, would not be able to be listed on any sites that depend on metadata (OpenSea/etc), and people would not be able to send money to that name because their wallet would auto-normalize to the non-extended ٠٠٣.eth and send there instead.
It’s the same thing that happens with capital characters. You could manually register the capital GOD.eth against the smart contracts, but it is not going to be valid and will be essentially useless because all clients will normalize to god.eth first.
4 Likes
Here is how I understood your suggestion, which I think would work:
-
we always do this mapping during normalization:
- 6F0 → 660
- 6F1 → 661
- 6F2 → 662
- 6F3 → 663
- 6F7 → 667
- 6F8 → 668
- 6F9 → 669
-
the second examples of case 1 and case 3 both normalize to their first examples
[661 662 663] and [661 662 664] -
in case 2 the second example normalizes to [661 662 6F4] and will be its own name, the first example remains as is.
In total you’d get 4 distinct names.
Do you see any other issues here?
2 Likes
Yeah that looks good to me. I agree with this mapping and I think this enables the most possible names and avoids the confusing ones.
4 Likes