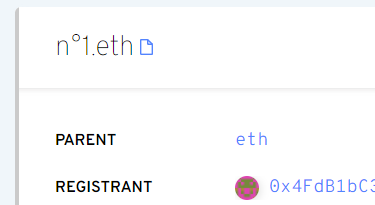
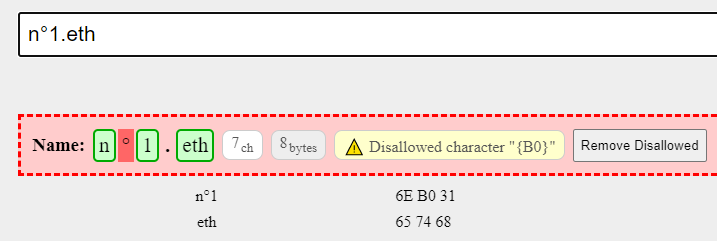
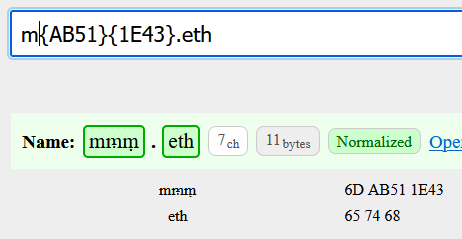
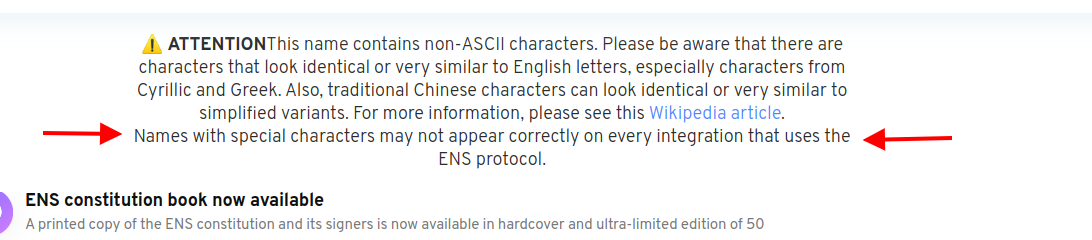
I see someone registered a 38894 character name (concatenation of integers 1-10000.) Also someone registered an enormous string of {110B} characters, which seems to break text/line/word/overflow-wrapping logic in all browsers (and my error report  ).
).
I noticed someone registered Arabic numbered domains (eg. 123 → ١٢٣.eth). I’m not sure I agree with UTS-46 and CheckBidi here, and I think they’re wrong:
UTS: A Bidi domain name is a domain name containing at least one character with Bidi_Class R, AL, or AN. See [IDNA2008] RFC 5893, Section 1.4.
Bidi: The first character must be a character with Bidi property L, R, or AL. If it has the R or AL property, it is an RTL label; if it has the L property, it is an LTR label.
A missing exception is: if the label is 100% AN (Arabic Number), it should be valid, as the direction is irrelevant (edit: maybe I’m wrong for 123 vs 321 vs 123RTL?)
I think the ContextJ change mentioned earlier is correct. With this change, ZWNJ will never appear in output and ZWJ only appear in emoji sequences. If you don’t care about silently erroring, this is equivalent to ignoring ZWNJ globally.
I keep going back and forth on a few decisions but I think I’ve chosen correctly after working through more cases. For example, I wasn’t completely sure if FE0E in ZWJ should be disallowed. It’s against the spec, but we already must allow normal emoji not in ZWJ sequences to use any emoji styling (because those names have been already registered and we don’t know styling they intended.) The example of 🚴♂1F6B4 200D 2642 vs 🚴︎♂ 1F6B4 FE0E 200D 2642 vs 🚴︎♂ 1F6B4 FE0E 2642 I think makes it clear that FE0F in ZWJ is bad. ZWJ sequences should always be styled.
I created validation tests: it contains hand-written tests (from demo examples), randomly generated tests (that utilize mapped and complex emoji), and real-world tests (from registered names.)
I’m less bullish on enabling $ now that I see 💲 already exists. Similarly, I overlooked ₤ when considering £. To be conservative, maybe only ₿ should be enabled? (since it was used in many registered names)
I collected more ENS names (nearly 1M) although I still think I’m missing some. If someone has a complete registered name snapshot, please send it my way.
I added some DNS comments to my ENSIP. I also worked through a collision possibility and made a post about it. I added the correct Punycode encoding to the resolver demo and made a simple Punycode tool (since all online tools apply some kind of Unicode normalization.)
I’m think done making code changes. I need a few more days to finish organizing the ENSIP document.
As I mentioned before, I’m not planning to include the single-script confusable logic in this release. After the discussion about input vs output confusables, the overall approach needs revised. To quickly recap: normalization must be idempotent. If normalize(normalize(a)) != normalize(a), all kinds of weird stuff happens. If you only catch confusables on the output, then you can’t catch confusing inputs, which is what end-users actually interact with, eg. Ⅷ vs VIII → viii. If you only catch confusables on input, then you can circumvent confusable detection using mixed case input, that leads to confusable output. So you have to check both places. I also dislike having to make opinionated decisions about the fates of peoples’ names.