This is definitely an issue, and clients should show the user the normalised form. You’re right that we need to update our docs to reflect this.
True; however, I think it’s more important to have a single consistent representation of each name that users will always see. This is also consistent with what browsers do - if you enter GOOGLE.COM, for example, it shows you the normalised google.com.
Wouldn’t on-input confusables also fail here, since they’re different characters? I’m also of the opinion that it’s less of an issue on the output, because the user can see what the normalised name looks like and if it matches their expectations.
How (if at all) are these examples handled at present?
I found another exotic emoji situation but I don’t think it has any consequence because of the ZWJ whitelist.
According to UTS-51, emoji_modifier_sequence = emoji_modifier_base emoji_modifier where both of those terms are defined as singular emoji characters (no styling.)
Examples:
261D 1F3FB → ☝ + 🏻 → ☝🏻
1F469 1F3FD 200D 2695 → (👩 + 🏽 → 👩🏽) + ⚕ →
However, Windows allows you to stick an FE0F (followed by an arbitrary amount of FE0E/FE0F) on the base emoji and then an arbitrary amount of FE0E/FE0F on the modifier emoji (including the mismatched case), and renders the sequences as identical:
If a ZWJ sequence ever started with a modifier, then you could construct a ZWJ sequence that appears as different sequences on different platforms:
(+FE0F)+(🏽+ZWJ+⚕️)
((+FE0F+🏽)+ZWJ+⚕️)
Instead of allowing non-standard emoji-styling on base and modifier, I assert that no whitelisted sequence can start with a modifier and that every base and modifier can be parsed without a FE0F.
In that latest error report, what does “diff-norm” mean? I see it’s all the punycode literals like xn--.... I’m assuming those names would also be considered invalid and fail normalization with your library?
I will have a section in the ENSIP about DNS compatibility.
I also think there should be a tool which determines if your name can be shuttled onto DNS (using latest standards) and if punycode is required.
They’re both invalid in the demo so I must not have record of them. I am using a set derived from a list Nick provided + capturing NameRegistered events since then. Can someone provide me full set of registered names as-of today?
Another weird one (probably not important): I can’t find a single example of ContextJ (allowing ZWNJ/ZWJ in specific circumstances) beyond the rule existing in UTS-46 and RFC 5892. There must exist names that require it in Arabic/Indic/Persian. Supposedly it induces a cursive rendering of the joined characters? It’s unclear to me if it alters the interpretation.
However, if the character has no joining character, does not support cursive, or font support is poor, then the ZWJ renders invisibly. I am now confused why UTS-46/IDNA makes such a big deal about this situation.
The following names are distinct yet look pixel-identical on all devices I own:
a्.eth vs a्.eth(61 94D 200D) (Latin+Devanagari) →
a्a्(61 94D 200D 61 94D) renders like two different-sized a's.
Helllo everyone,
First post
I didn’t get to my introduction yet will do that later so I figured I would start here as this thread is something close to me with mostly registering names with contract calls directly myself for access to larger character sets.
Finally made it through this whole thread to see if any of my thoughts had been mentioned or brought up regarding some specific characters.
I’ve quoted some replies in the thread which I feel are relevant.
Some characters obviously pose greater risk than others.
Though any previous registrations would have been done on the contract directly these names were visible until recently as seen with @@@.eth below with a previous opensea sale of 0.88E.
All of these names currently owned and are disallowed by the ENS metadata and show “no data available”.
I think these names should simply have a warning on them / whitelisted. Some have been registered recent but I think almost all have previous registrations and at least one with a “high” sale record.
Certain characters like \ maybe / for example should be handled with more care as they can be used in character escape sequences for injecting data into unsuspecting UI’s.
Or possibly allow repeating lengths of N of certain disallowed characters while simply disallowing if < N. So people can register 3, 4, 5+ of them but maybe not allow creating valid escape sequences etc.
Exactly and whats easier that simply typing: !!!, @@@, ###, $$$, ***, &&& etc
I think these should be considered valid characters for “display purposes” in the ENS metadata backend. Meaning with the “! warning” as is done with emoji and non ascii names … with the recent hype around numbers names we can see the simple patterned characters are in fact very desirable even if there is no perceived valid use case aside from aesthetically pleasing.
Sometimes I completely forget that the goal is to have the names resolve in browsers I suppose. I’m still simply on the identity & username thing
Also what I mean is … the current behavior actually prevents those tokens from “existing” at all which seems a bit counter to a lot of what I’ve read about memorable names etc. They display “no data available” on metadata service so they can not be resolved or managed “on-chain” to any addresses.
Currently they are blocked at the metadata layer from even existing. The metadata layer could add them to the “non-normalized” list by matching >= 3 repeating of any character and adding them to a special array that is not to be displayed in browsers but allows them to “exist” on-chain / doesnt block them there.
Then it would once again be up to the clients if they want to display non standard/non-normalized names or not or restrict to the standard of normalized.
I just think we should be careful about restricting names to solely DNS & URL schemes as they are neither of those things. They are those and more.
They should be able to exist on the contract level really I think. I should be able to name my contract if I own !!!.eth (and hope some wallet providers allow non-normalized names in payments … but thats not the point). Not all names should need to resolve as a URL but all names should be able to exist?
While I do understand your original point also! So I understand if its never to be if browsers are the main focus.
Just to be clear, I am not an authority on these choices. Enabling _$£¥€₿ (and other decisions) is my recommendation.
Regarding #*!@%&: I don’t see why you’d want to deprive future ENS applications of user(@)ens, ens(#)hash, or ens(?)query=a(&)b=c just to claim a 3-letter name. Additionally, (*) is already widely recognized as wildcard and (%) is used for escape.
I think you could make an argument for (!) or maybe (%), and equally an argument against (-) and (_) (especially when adjacent, eg. ___.eth vs ____.eth), but market price should have nothing to do with it.
It is not about “claiming 3 letter names”. It is about memorability and names >= 3 characters since that is the only “restriction” in the contract so all names that can be should be on the contract level is all.
Once again, on the metadata level it should be possible to match >= 3 of any /repeating/ character and still disallow if <= 2 so they can exist in a “non-normalized” state which shouldn’t be displayed in any ENS applications / dApps following the standards / documentation.
Displaying non-normalized names could be defined as leading to undefined behavior or so and applications doing so should have that option but understand it could break things.
I don’t think that would be depriving anyone of anything if they are simply added to non-normalized that way and able to exist on the contract level again with metadata.
Market price has nothing to do with easily repeated character names that are on the tops of everyones keyboards and I think people would like to use them if possible or at least have them exist in metadata rather… Mentioning the names were sold at some point was simply showing that multiple people like those names and “want” them and have used them in the past.
Edit before sleep:
My point is what you and Nick are describing sounds like a web3 replacement for DNS but restricted by web2 rules. Which doesn’t make sense for a web3 contract / protocol that is much more than that working on the same level as dns, urls, and browsers… While I understand the NEED to be in compliance WITH those protocols simultaneously though.
I believe we should allow-but-remove ZWJ/ZWNJ in ContextJ (making them optional). This would mean ZWJ only ever appear inside valid emoji sequences. In the text-only case, you can simply disallow ZWNJ/ZWJ, and you’ll produce the same normalized form.
I think most importantly is getting this update out soon, considering the staggering amounts of new registrations ENS is getting right now, rather than getting bogged down in the discussion of every weird Unicode edge case, which I am sure there are a lot more of.
If we look at recent sales, there is sadly a lot of fakes being bought that contain illegally placed ZWJs in non emoji context and people are rightfully frustrated.
Also since many apps like Opensea, Metamask and Etherscan are not using the same normalization standard than the ENS frontend, many users are experiencing names that are getting delisted afterwards or are not searchable: Seemingly valid names are being reported as invalid by metadata service · Issue #71 · ensdomains/ens-metadata-service · GitHub
In addition, it makes it very hard for us collectors since symbols like the .eth club are not filterable on Opensea, same with many other emojis. The market for these is growing rapidly aswell.
The community in the biggest collectors Discord are already using raffy’s current demo implementation to point to users as the new standard for checking frauds.
I believe raffy has demonstrated here in this thread and with his implementations of the normalization (and the excellent documentation, which as a software dev myself I do appreciate a lot ) that he knows best what a standardized future proof normalization should look like for ENS, and I think his recommendations have been spot on so far. His latest error report clearly shows the improvements made with the new implementation by filtering out the “junk”.
I think ENS and the currently rising collectors of ENS domains would benefit a lot if raffy’s open source normalization update came out soon as other third party apps like X2Y2, Gem.xyz and ens.vision to name a few are currently working on their own normalizations to make many Unicode registrations searchable (emoji digits, emoji single, doubles and triples), but this fragmentation between normalizations will only hurt us since it is not standarized across all apps which leads to fragmentation and bad user experience.
I’m not sure what you mean by this? The names do exist on chain. The metadata service doesn’t return info about non-normalised names (or a few other sanity rules that we’ll be harmonising when this new normalisation function is fixed) in order to protect users from buying names that won’t resolve.
I think the reverse: It’s much easier to start cautious and get more permissive over time, than vice-versa.

 +
+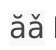



 .eth club are not filterable on Opensea, same with many other emojis. The market for these is growing rapidly aswell.
.eth club are not filterable on Opensea, same with many other emojis. The market for these is growing rapidly aswell. ) that he knows best what a standardized future proof normalization should look like for ENS, and I think his recommendations have been spot on so far. His
) that he knows best what a standardized future proof normalization should look like for ENS, and I think his recommendations have been spot on so far. His