FYI that version of ensjs is (pretty much) deprecated
Gotcha okay! Should that be removed here? It’s the first library listed: ENS Libraries - ENS Documentation
Should people be using ethers.js instead? Because ethers.js doesn’t appear to use our normalization code at all, they’ve rolled their own IDNA-compliant nameprep method, which would probably have a whole different set of valid/invalid names in @raffy’s report.
And web3.js appears to use @ensdomains/ens, which in turn uses… dun dun dun… the old eth-ens-namehash 2.0.8.
And web3.js’s sub-package web3-eth-ens also uses the old library: https://github.com/ChainSafe/web3.js/blob/1.x/packages/web3-eth-ens/package.json#L18
2 Likes
Not technically deprecated just yet, but it isn’t maintained actively and we are developing a new version to replace it.
I’ll look into this. The general recommendation for basic ENS usage is ethers, so it should be following the standard.
Theoretically this is an easy fix, one of the other TNL devs is currently working on the web3 codebase so they might be able to do this.
3 Likes
Thanks! Here’s the IDNA nameprep implementation in ethers.js: https://github.com/ethers-io/ethers.js/blob/master/packages/strings/src.ts/idna.ts#L157
They also have their own namehash implementation where that nameprep gets used: https://github.com/ethers-io/ethers.js/blob/master/packages/hash/src.ts/namehash.ts#L27
1 Like
What characters are these? Upper-case latin (ASCII)? Or something else?
I’m in touch with Ricmoo, who is planning to adopt this library once it’s ready.
2 Likes
Got it. Most of the names seem to fall into this category of using unusual letters like “small capital” letters. Personally I’m okay with making these invalid.
3 Likes
Another to block - U+2800 “Braille Pattern Blank”, which appears as a space and appears to be allowed under the current normalisation: https://twitter.com/nicksdjohnson/status/1513786864662364162
2 Likes
This is disallowed in IDNA 2008 (it has flag NV8).
I think we should disallow 0332 (COMBINING LOW LINE) → Example: b̲e̲e̲r̲.eth
I think we should allow the striked+capital currency characters: $£¥€₿.
The makeshift currency symbol for Ethereum Ξ (Xi) is already allowed (but casefolded during normalization). The only modification it needs is a script conversion from Greek to Common (if single-script logic is used.)
I have the single-script code working in ens-normalize but it’s a little goofy to derive the necessary data when building from scratch, as you need to build the library without single-script logic first, to derive the confusable table, which is then combined with the canonical confusable overrides and fed back into the library to build the final version. I’ll push once I resolve the build process.
If anyone has experience with non-Latin scripts, here is a list of single-script confusable collisions by script (post normalization).
Schema: Script → Confusable → Array of Matches
For each confusable, I need someone to review them (except Latin) make the follow decision:
- remain unchained (no canonical, all confusable)
- reduce to 1 result (canonical choice)
- reduce to 0 results (ignored)
For example:
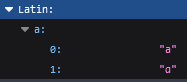
The answer would be: (Decision 2) “a” → [“a”]
2 Likes
Very Rough Algorithm Outline
Normalization Algorithm
Transform a string into a normalized string. String padding (\s+) should be removed by the user. Various errors may be thrown during computation.
Example Input: 💩Raffy.eth
-
Tokenize the string into a list labels, where each label is a list of
EmojiandTexttokens, where each token contains codepoints:[ [Emoji(1F4A9), Text(52, 61, 66, 66, 79)], [Text(65, 74, 68)] ]
-
Decode and Validate each label:
Token[]→Token[][Emoji(1F4A9), Text(52, 61, 66, 66, 79)]→ no change[Text(65, 74, 68)]→ no change
-
Flatten each label into a list of codepoints joined together with
$PRIMARY_STOPand interpret as a string.[1F4A9 52 61 66 66 79] + 2E + [65 74 68]
-
[CheckBidi] If the resulting string is Bidi domain name (any token contains a codepoint of BIDI class R, AL, or AN) and the Textual Content of any label fails RFC5893, throw an error. (Specification, Code)
Example Output: 💩raffy.eth
Tokenize
Return a list of labels by repeatedly processing and consuming the prefix of string until empty. Emitted tokens are appended to the last label. The list of labels initially contains a single empty label: [[]]. Labels can be empty.
Essentially UTS-51 parsing is done first, followed by UTS-46 w/IDNA 2008 (std3=true, transitional=false, +NV8, +XV8, and exceptions listed below.)
Apply the following cases, starting from the top after each match:
-
If the prefix is an exact match of a whitelisted emoji sequence, pop the match, and emit an verbatim
Emojitoken (one that contains the matching codepoints.) -
If the prefix is an emoji flag sequence, pop the match, and emit an verbatim
Emojitoken. -
Determine if the prefix is an emoji keycap sequence:
Caution: Under EIP-137 (commonly implemented as UTS-46 w/IDNA 2003),# FE0F 20E3normalizes to# 20E3(asFE0Fis ignored) but normalizing# 20E3again is an error. A REQ/OPT distinction preserves idempotency and makes keycap handling future-proof. The malformed 0-9 keycaps are effectively grandfathered.
$KEYCAP_OPT = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
$KEYCAP_REQ = [#, *]- If the prefix is
$KEYCAP_REQ FE0F 20E3, where$KEYCAP_REQis a codepoint, pop the match, and emit an verbatimEmojitoken. - If the prefix is
$KEYCAP_OPT FE0F? 20E3, whereFE0Fis optional and$KEYCAP_OPTis a codepoint, pop the match, and emitEmoji($KEYCAP_OPT, 20E3).
- If the prefix is
-
Determine if the prefix is a ZWJ sequence or a single ModPre. ZWJ sequences are whitelisted as sequences of ModPre joined by
$ZWJ. Consume and emit the longest match as singleEmojitoken.- Determine if the prefix is a ModPre:
An emoji sequence isemoji_zwj_sequence | emoji_tag_sequence | emoji_core_sequence.
An emoji core sequence isemoji_presentation_sequence | emoji_keycap_sequence | emoji_modifier_sequence | emoji_flag_sequence.
Since flags and keycaps have already been processed, only modifier and presentation sequences remain.
- If the prefix is an emoji_modifier_sequence, pop the match, and emit an verbatim
Emojitoken. - Determine if the prefix is an emoji_presentation_sequence:
Caution: Backwards compatibility with EIP-137 is maintained by permitting some emoji to optionally matchFE0Fbut tokenize without it (DROP). ZWJ and future emoji require (and always include)FE0F(REQ). - If the prefix is
$STYLE_REQ FE0Fand$STYLE_REQis a codepoint, pop the match, and an verbatimEmojitoken. - If the prefix is
$STYLE_DROP FE0F?whereFE0Fis optional and$STYLE_DROPis an codepoint, pop the match, and emitEmoji($STYLE_DROP).
- Determine if the prefix is a ModPre:
-
If the prefix is
$STOP, pop the match, append a new label, and continue. -
If the prefix is
$IGNORED, pop the match, and continue. -
If the prefix is
$VALID, pop the match, and emit a verbatimTexttoken. -
If the prefix is
$MAPPED, pop the match, and emitText(map[$MAPPED])wheremap::codepoint→codepoint[]. -
The prefix is character is invalid. Throw an error.
Decode and Validate
Transform a label (list of Emoji/Text tokens) into a valid label.
- Flatten the tokens into a list of codepoints, where
Emojitoken codepoints are used verbatim andTexttoken codepoints are converted using Normalization Form C. - If the resulting sequence starts
78 6E $HYPHEN $HYPHEN("xn--"):- Decode the remainder of the sequence as Punycode (RFC3492). (Specification, Code)
- If decoding failed, throw an error.
- Tokenize the decoded the sequence where
$STOP,$IGNORED, and$MAPPEDare empty sets. - If tokenization failed, throw an error.
- Flatten the tokens to a list of codepoints like above.
- If flattened sequence doesn’t exactly match the decoded sequence, throw an error.
- Replace the initial tokens and flattened sequence with the decoded values.
- If the sequence is empty, return an empty list.
- If the sequence has
$HYPHENat 3rd and 4th codepoints, throw an error. - If the sequence starts with
$HYPHEN, throw an error. - If the sequence ends with
$HYPHEN, throw an error. - If the sequence starts with
$COMBINING_MARK, throw an error. - [ContextJ/ContextO] If the Textual Content fails RFC5892, throw an error. (Specification, Code)
- Return the tokens.
Textual Content of a Label
Flatten the tokens into list of codepoints, where Text token codepoints are converted using Normalization Form C and Emoji tokens before the first Text token are ignored, and replaced by FE0F afterwards.
This prevents emoji from interacting incorrectly with Bidi and Context rules.
Defined Variables
$PRIMARY_STOP = 2E$HYPHEN = 2D$ZWJ = 200D$STOP = [2E]$VALID, $MAPPED, $IGNORED→ IdnaMappingTable$COMBINING_MARK→ DerivedGeneralCategory matchingM*- Custom ens-normalize Rules
- Derived Rules (UTS46 + UTS51)
3 Likes
This looks good, thank you. It looks like a good start to an ENSIP.
I’m not sure we should decode punycode sequences. That would be a change from how we handle things at present, where punycode isn’t interpreted at all.
I started to format the information like an ENSIP (still a WIP). Instead of explaining my implementation in words, I decided to explain the modifications and gotchas first, and then illustrate the tokenized version in psuedo-code as separate section.
This was my issue with punycode all throughout this thread. UTS-46 specifically has punycode decoding. I also agree we should remove it. I will take this as opportunity to do so.
However the presence of undecoded punycode will still throw an error because:
- CheckHyphens disallows
--at position 3,4 - In unstructed text, there’s no way to know if
xn--ls8his puny or literal
As an ENS holder and especially interested in collecting exotic domains (emojis, etc.) I was wondering when it will be possible to incorporate emojis from the 14.0 Unicode standard into the app. These are already in use in the newest iOS and Android versions.
For example:
https://app.ens.domains/search/%F0%9F%AB%A0%F0%9F%AB%A0%F0%9F%AB%A0.eth
The full suite of such emojis can be found here: Emoji Version 14.0 List
Having read the whole thread so far I want to applaud raffy very much for his efforts in this matter. His technical understanding of the Unicode standard and its quirks is very remarkable. His draft I believe is a much needed clarification and update to the older ENSIP standard from 2016 and brings much needed additions to the protocol that would reduce many ambiguities that are present in the current implementation.
I would be very much in favor for raffy being compensated for his extensive work here and I am very eager to see this draft implemented into the protocol soon.
2 Likes
We should probably remove that check too, if punycode has no special meaning.
Since we don’t recognise punycode, it’s always literal.
1 Like
-
CheckHyphens should just be false then? I see no issue with arbitrary hyphen placement. For example, underscore will be able to go anywhere. The DNS comment in ENSIP-1 seems to imply that CheckHyphens was intended to be false? as there’s a warning about starting/ending hyphens for DNS compatibility.
-
Should whitespace be ignored instead of an error? IDNA with UseSTD3ASCIIRules=true) disallows almost all whitespace. I was writing a section about preprocessing but noticed you can safely replace all whitespace with empty string. Example:
" raffy.eth " == " r affy.eth" == "raffy.eth". -
I’m writing my ENSIP in terms of modifications to UTS-51 and UTS-46, which makes the algorithm appear somewhat complicated. If we supply a derived file (similar to this one) which contains all of the character sets (valid, mapped, ignored, stops, combining marks, various emoji classes, whitelisted sequences, zwj sequences, etc.), I believe the implementation is pretty straight forward.
2 Likes
Yes, it should be false - though as noted, names that violate it may not work via gateways such as eth.link and eth.limo.
It should result in an error - though clients should probably strip leading and trailing whitespace before normalisation for user convenience.
That sounds like a good idea.
1 Like
I’m still uncertain if only catching confusables in the output/normalized form is sufficient but it greatly simplifies the problem. All you need is a mapping from normalized characters to scripts (to determine if a label is single-script), additional disallowed single characters (which are just extra IDNA rules), and a small list of 2-4 length character sequences (~400) that are also disallowed anywhere in the output label.
Here is an ornate example I found where you have confusability on the input (that isn’t covered by UTS-39 because it’s an emoji+text situation) but clearly different on the output (using proposed normalization, without additional logic.)
Text-styled regional indicators potentially render as small-cap ASCII:

// default emoji-styled
1F1FA 1F1F8 = "🇺🇸" => "🇺🇸" // 2x regional (valid flag sequence)
1F1FA 1F1F9 = "🇺🇹" // 2x regional (invalid flag sequence)
// explicit emoji styling
1F1FA FE0F 1F1F8 FE0F = "🇺🇸" // same
// explicit text styling
1F1FA FE0E 1F1F8 FE0E = "🇺︎🇸︎" // small-caps ASCII (no flag)
// confusing example
62 1F1F4 FE0E 1F1F8 FE0E 73 = "b🇴︎🇸︎s" vs "boss" // before normalization
= "b🇴🇸s" // after normalization (FE0E is dropped)
![]()
1 Like
Do you have reason to believe it’s insufficient, or just the impression that you may not have explored the entire design space here?
I think the issue boils down to whether the end-user ever sees the normalized form:
-
If I enter
R𝔄𝔉𝔉𝔜.ethinto app.ens.domains, I get sent toraffy.eth. In this situation, the end-user directly observes the normalized form. -
If I type
R𝔄𝔉𝔉𝔜.ethinto Metamask send, I get my eth address and the letters𝔄𝔉𝔉𝔜are highlighted red but I do not see the normalized form. With this UX, there are certainly inputs that are confusable that result in outputs that are not. -
The UX guidelines don’t comment about this.
The primary issue with showing the normalized form is that it mangles some names, which might be confusing to end-users.
I also am unsure how frequently ENS users use/share a valid but non-normalized variant of their ENS name. Some of these permutations may violate the confusable rules but I have no way of checking (without generating all permutations of registered labels.).
-
10L.ethvs10l.eth -
atmo.ethvsA™O.eth(not confusable but you get the idea)
On-input would mean normalization throws on names that are confusable on input without any processing:
- Need the full set of confusables (not just the casefolded normalized ones)
- Are
XⅩ𝐗𝑋𝑿𝒳𝓧𝔛𝕏𝖃𝖷𝗫𝘟𝙓𝚇actually confusing if they all map tox? I’d say no. - Need to check if the output is also confusable as the normalized form might become confusable after normalization. eg.
Ɑ.ethisn’t confusable (2C6D Latin Capital Letter Alpha) but it’s normalized formɑ.ethis.
Here’s an example where on-output confusables will fail: ⒸⒸⒸ.eth =!= ©©©.eth
Ⓒ (24B8) normalizes to "c" (63)© (A9 FE0E?) normalizes to "©" (A9)©️ (A9 FE0F) normalizes to "©" (A9)
After writing this, I think I need to check both input and output, and revise the numbers I computed above.
2 Likes
Revisiting the confusable stuff: this unpolished report shows for each script, which input characters correspond to confusables that map to 2+ output characters. The character left of the arrow is the normalized form of the group. Each colored character has a tooltip for name, script, and codepoints.
A grouping is red if the mapping changes the script when normalized. If the input label is single-script, then applying normalization will introduce a new script, so that the output label will not be single-script (unless all of this type).
The default decision would be to disallow all of these characters. Manual exceptions should be made when there is an obvious choice (like ASCII) but the choice isn’t clear in some cases and I don’t know how to do resolve the non-Latin scripts.
Here are a few examples:
-
Latin Small “c” has 2 possibilities, clearly the ASCII C should be allowed and the small-capital C should be disallowed. Likely, most (all?) the small capitals should be disallowed.
-
Latin Capital “A” with U-thingy has 2 possibilities: I don’t know which one should be canonical, probably disallow both?


Like the circled-C example above, here is another example that would pass on-output filtering (because of IDNA mapping) but would correctly be handled if you check both input and output:

"lll" (6C 6C 6C Latin Small L)"Ⅲ" (2162 Roman Numeral Three) normalizes to "iii"- Note:
iandlwont confuse because they’re ASCII
I’m assuming this is the right choice? -
LLL.eth,lll.eth,iii.ethare fine -
Ⅲ.ethwould fail (input: fail, output: pass). - Note: I don’t know if the owner of
iii.ethusesⅢ.eth
I probably would because it’s a single character. - It’s possible this confusable should be ignored.
The above stuff looks insane, but as I said before, it essentially reduces to just a list of disallowed characters and sequences. The hard part is deriving that list.
3 Likes