For the hypothetical situation of single-script confusables, there are two minor issues.
1.) There are characters that IDNA maps from a single character in a script to multiple characters in multiple scripts.
// these seem tame since Common is just a bag of junk
[0140:Latin] is mapped to [6C:Latin][B7:Common]
[32C7:Common] is mapped to [0038:Common][6708:Han]
// this is weird
[33A5:Common] is mapped to [03BC:Greek][6D:Latin]
2.) There are characters that NFC maps from one script to another.
[1FEF:Greek] is normalized to [60:Common]
This just means the input scripts can be different from the NFC’d scripts and different from the output (normalized) scripts.
The most likely place you’d implement script-based restrictions is on the output, but there might be situations where you enter a Greek-only name, it gets transformed into Greek+Something during NFC/normalization, and then fails the single-script requirement for a non-obvious reason.
I can take all registered labels, find the valid normalized names, choose the names that span a single script, and see how many contain characters that have normalizable confusables with other characters in that same script.
There appears to be very few names that aren’t confusable in some way even when you require that the input is a single scripts.
Single Script
# pure = number of labels that only use the specified script
# safe = number of pure labels where no character has a confusable
{
Latin: { pure: 489067, safe: 7},
Han: { pure: 1063, safe: 266},
Common: { pure: 8071, safe: 4819},
Thai: { pure: 25, safe: 4},
Arabic: { pure: 127, safe: 0},
Cyrillic: { pure: 277, safe: 89},
Devanagari: { pure: 18, safe: 10},
Greek: { pure: 24, safe: 8},
Hebrew: { pure: 22, safe: 0},
Canadian_Aboriginal: { pure: 1, safe: 0},
Tibetan: { pure: 4, safe: 0},
Tamil: { pure: 2, safe: 0}
}
The following scripts have no registered names with same-script confusables:
{
Katakana: { pure: 60, safe: 60},
Egyptian_Hieroglyphs: { pure: 43, safe: 43},
Hangul: { pure: 211, safe: 211},
Ethiopic: { pure: 4, safe: 4},
Hiragana: { pure: 18, safe: 18},
Runic: { pure: 2, safe: 2},
Gurmukhi: { pure: 2, safe: 2},
Georgian: { pure: 1, safe: 1},
Lisu: { pure: 1, safe: 1},
Vai: { pure: 1, safe: 1},
Phoenician: { pure: 1, safe: 1},
Old_Italic: { pure: 1, safe: 1},
Lao: { pure: 1, safe: 1}
}
Single Script + Common
{
Latin: { pure: 538776, safe: 13 },
Han: { pure: 1105, safe: 299 },
Common: { pure: 8071, safe: 4922 },
Thai: { pure: 25, safe: 4 },
Arabic: { pure: 132, safe: 1 },
Inherited: { pure: 1870, safe: 1870 },
Hangul: { pure: 214, safe: 214 },
Katakana: { pure: 114, safe: 114 },
Cyrillic: { pure: 283, safe: 90 },
Devanagari: { pure: 19, safe: 10 },
Greek: { pure: 26, safe: 9 },
Egyptian_Hieroglyphs: { pure: 43, safe: 43 },
Runic: { pure: 3, safe: 3 },
Ethiopic: { pure: 4, safe: 4 },
Hebrew: { pure: 22, safe: 0 },
Hiragana: { pure: 21, safe: 21 },
Coptic: { pure: 1, safe: 1 },
Canadian_Aboriginal: { pure: 1, safe: 0 },
Gurmukhi: { pure: 2, safe: 2 },
Georgian: { pure: 1, safe: 1 },
Tibetan: { pure: 4, safe: 0 },
Lisu: { pure: 1, safe: 1 },
Tamil: { pure: 2, safe: 2 },
Vai: { pure: 1, safe: 1 },
undefined: { pure: 1, safe: 1 },
Phoenician: { pure: 1, safe: 1 },
Old_Italic: { pure: 1, safe: 1 },
Lao: { pure: 1, safe: 1 }
}
I’ll try this again with a more relaxed set of confusables.


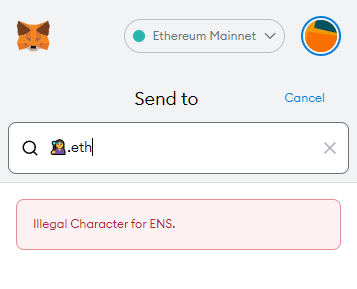
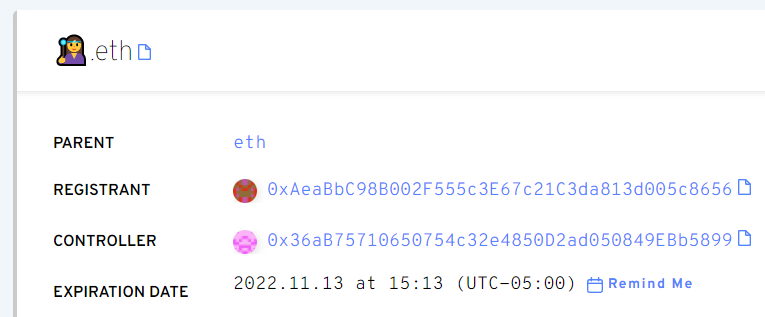
 .eth is marked as invalid in the ens-error section, which matches up with Metamask:
.eth is marked as invalid in the ens-error section, which matches up with Metamask: