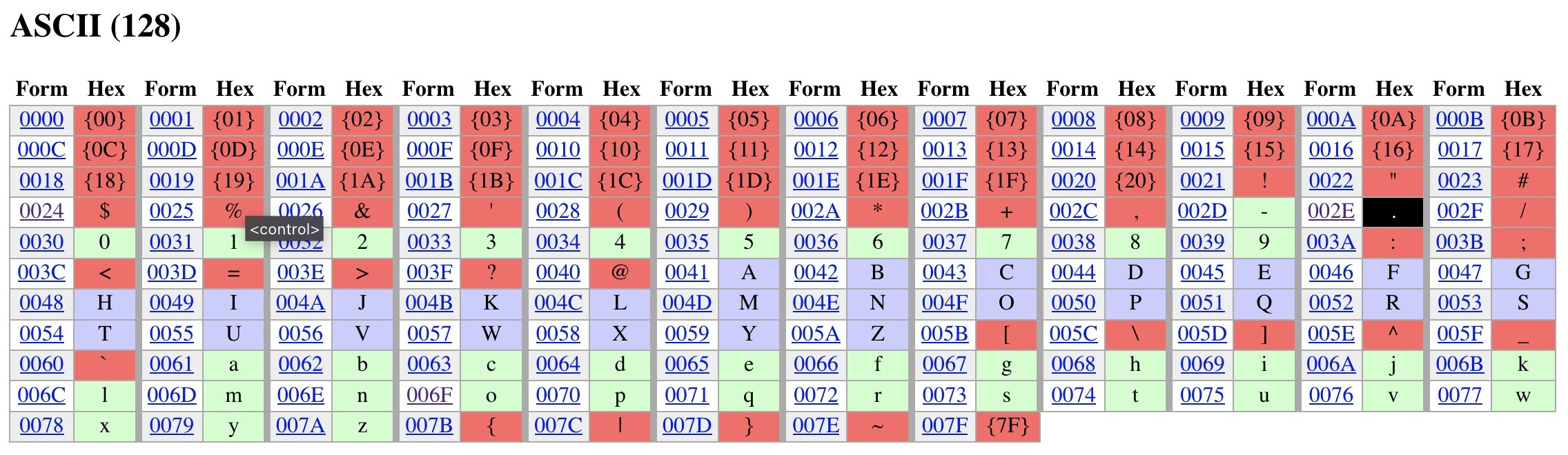
Is there a key to the meaning of the colors here? There are a few green ones I wouldn’t expect to be allowed (such as quotation marks) and many red ones that seem harmless.
This seems reasonable, as long as we can ensure we don’t deploy a version that will cause legitimate existing names to stop resolving.
As it stands, we can’t prohibit registration of domains, only make them unresolvable - so we couldn’t auction them off. This would change if raffy succeeds in making an EVM implementation of his algorithm.
I wanted to avoid this situation but there’s no algorithmic solution that prevents malicious use. Personally, I was really disappointed in how Unicode handled emoji. Even the choice of reusing ZWJ, rather than have a separate visible character that goes invisible when supported, was an enormous UX mistake.
I decorated it using the IDNA 2008 rules. I’ll add a key, it’s the same coloring I’m using everywhere: green=valid, purple=mapped, red=invalid, gray=ignored, black=special.
Are you saying prohibiting the registration of scam names would change/be possible, or that it would change that ENS would auction off new emoji domains when they come out?
BTW @raffy I remember seeing emojis used in smart contracts and in token names when looking on etherscan. Would this make it easier for the whitelist or does it make it simpler to write?
From the start, ens-normalize was developed under the idea that I would make an on-chain version, as that was the original motivation. I wrote a simple version a while ago, but decided that any development time is wasted until the spec is figured out. The original compression method would of worked in solidity, but the latest version of the library uses an arithmetic compressor, which would not be gas efficient.
The client-side callable version is relatively straight forward, as the full payload is only 12KB, but the main value of an on-chain algorithm would be able to call it efficiently during a transaction. For this, you’d need a clean implementation with aggressive short circuiting, so the common cases are efficient.
The dream would be an upgradeable contract but the Unicode release cycle is every 2 years? so I think the smarter goal is just making a good reference implementation, that has a simple implementation, that can be ported everywhere w/o ambiguity (unlike most Unicode implementations), and then write the EVM version.
I haven’t been able to figure out a solution to confusable problem. I think the script idea above is valid but breaking Common/Latin/Greek/Cyrillic into smarter groups has proven very difficult. Possibly I was just aiming for something that requires too much investment.
There are many Unicode symbols that look visually identical, even after UTS-46 is applied. Some of these exist between separate scripts. Some are within the same script.
AFAIK, the best algorithm for dealing with this problem is outlined in the Google Chromium documentation. Unfortunately, many of the techniques involve using the punycode-form to indicate that the input name is potentially confusing.
If ENS used the punycode solution, it would mean there are 3 possible states for a name post-normalization: (1) an invalid name, (2) a confusable name (punycode), or (3) a valid name. Both (2) and (3) would be reachable. I’m not against this idea, I simply didn’t consider it, but it’s certainly possible.
UTS-39 and the Chrome solution also implement script-based restrictions. DNS has the advantage that traditional TLDs are country-based which means there’s an implicit script-set associated with many TLDs which can help resolve script ambiguities. .eth is international (similar to newer TLDs) and has no implicit script.
Even if ENS uses the most strict script-based technique (one script per label) there exist labels that look visually similar. As a native English user, most examples I’m aware of exist between the Common/Latin/Greek/Cyrillic scripts.
My idea was to split Common/Latin/Greek/Cyrillic into a better groups, such that script-restrictions would work AND prevent the obvious cross-script confusables. I’ve discussed this earlier in the thread. I haven’t been able to satisfactorily construct these groups.
That’s probably worth exploring. I’ve looked at the statistics for replacements and scripts in the registered labels, but haven’t measured how confusable they are. Computing which character in a confusable group is used most frequently (other than the preferred) is probably also useful.
I’m new to the forum but I’ve been looking at the ENS project for a while and wanted to make a suggestion regarding this issue in particular.
There is a known issue with people being led astray by way of ENS names with zerowidth characters and other shenanigans, it isn’t particularly hidden either and clients (opensea etc) are signalling this loudly to their users with ugly triangles warning of names that contain non-ascii characters.
There’s been extensive discussion here about the subject and I see you’re leaning strongly towards in-client normalisation and a library etc, I think that approach is going to have problems because you can’t force clients to use your library and people can interact with the contract directly and find loopholes.
I think that you have a complicated problem on your hands and, for now, it might be a good solution to launch a new extension, perhaps .ens, with character restrictions enforced on-chain and permitting only a-z0-9 ascii characters. That eliminates a whole ton of issues and provides some separation between the perhaps-slightly-tainted .eth name and makes it abundantly clear that the zwj issues won’t occur with the new extension. Your exponentialpriceoracle when applied to a new extension should produce strong capital inflows.
Then you can solve the .eth normalisation issue in time.
Also, I was thinking about your normalisation issue a lot and I’m not confident that’s a problem you can solve in code.
You’ll have issues where somebody registers an emoji string of three black-haired women and someone else tries to spoof it by registering two black-haired women with a brown-haired woman sandwiched between them.
There’s about three different cat emojis now and they all render differently on different platforms. Some updated platforms render the three different ones the same using the ‘primary’ cat emoji. The gun emoji famously renders as a waterpistol on iOS.
If you really really do want to allow emojis, thinking about it as a developer, bearing in mind that the purpose of a name is to be uniquely distinguishable, I’d want to go with a manually selected whitelist, and you’re going to get grief about your selections. For example, I’d permit only the generic ‘yellow’ character emoji, because if you allow once ‘skintone’ emoji you’re going to face pressure to allow all skintone emojis, which would be great in theory but if someone tells me ‘my ether name is a brown girl emoji’ I can’t reliably pick that one out of a list without at least something to compare with. And then you have colourblind users…
For that reason I’d go with a strict whitelist, and a short one at that.
That also generates premiums. If you limit the system to, for example, text-only domains or emoji domains which must contain three emojis from a short whitelist of emojis… then you’ll see some premium prices. You still have a huge set to sell from and you eliminate the case of one guy buying three hearts and the next guy buying 4 hearts… you eliminate so much potential user confusion and that’s so vital.
It should be remembered that the use case for most users revolves around fund transfers. Most people want their fund transfer ecosystem to be strict and regimented and with little room for error. SWIFT allows a very limited set of characters in their MT103s for good reason.
This is similar to the opinion I’ve reached: the original EIP is insufficient, even when implemented correctly (what ens-normalize does), there is a spoofing problem with confusables that can’t be solved without significant effort (lots of labor, multiple people, many opinionated decisions, etc.) The problem is double-hard considering names already exist, and we only have access to their “normalized” equivalents, not what owners/users typically input.
My development has stalled because I don’t know to solve this problem.
The counterpoint to the external library concern is that if we had a spec that solved the problem, we could try implementing it on-chain. However, this requires first having a spec then devising a clever way to encode it efficiently.
Regarding the currency symbol question, I agree those symbols should be allowed. As I’ve reiterated a few times in this thread, I think there are many characters that should be allowed and others that should of never been allowed. Keeping track of these characters, beyond a few edits, becomes a very complex task because the rules become conditional on one another as you organize.
I have an ENS name which does not resolve due to there being emoji’s in the name (livepeer:rocket:.eth)
It does not resolve using ethers, but interestingly enough 1inch does show the domain name and avatar correctly. This website shows no problems as well: ENS Resolver
Since I need to support any ENS name on my project, what is the recommended way to fix this? I just want to be able to get related ENS info and do not care if any names can get confused with each other.
I am not part of the project, I am just an observer, but from what I can see the resolution is performed differently by different clients. There is an official ENS resolution service (ens-metadata-service) available but different clients are using different standards and opting not to resolve names with emojis and certain characters because of the potential for confusion.
If you want a name that will resolve across 100% of ENS-supporting platforms I can only suggest you register an 100% ascii name. That is pretty much guaranteed to work regardless of what decisions are made in the future.
I remind you that this is my opinion and I am not a project member.
Normalisation is part of the resolution process, as is hashing. If a client doesn’t implement that correctly, it won’t resolve ENS names correctly. There’s not a security issue with doing this offchain, or much of an advantage to doing it onchain at registration time (and some significant issues trying to do it onchain!)
Clients don’t need to use our library, but they do need to adhere to the specs to be compliant.
One thing we definitely need to do is publish a more comprehensive test suite with a variety of input names and their correct namehashes, so clients can more easily do compliance testing.
The ENS DAO constitution also prohibits creating a new TLD as you describe.
This is definitely a risk with using Emoji names; there are a large number of emoji and some are confusable. Anyone registering a name needs to be aware of this. We could prohibit, eg, skin tone modifiers in emoji, but as you point out there are other confusable characters. I think educating people about the risks of emoji names is better than trying to regulate them here; people generally use them as decorative/meme-y names and aren’t relying on people entering them correctly or distinguishing them from each other the same way they do with ‘regular’ text names.
This is not intended to be used for resolving names. Clients should use ethers’ or web3’s built-in support for name resolution.
Those two emoji 1F680 1F311 are disallowed in IDNA 2008. They only would be allowed through using IDNA 2003 or using UTS-51 (emoji) like ens-normalize does.
Thanks! I guess I’ll just register a new ENS name and add a disclaimer to my website about being carefull when choosing a ENS domain. It’s a real bummer these kind of things are not being made clear to the user during the registering process…
 .eth)
.eth)