I think those objectives seem reasonable. And I agree the decisions should hinge on concrete numbers and the damage caused to existing names.
1 Like
-
All Pictographs (non-emoji) and Emoji according to 2003, 2008 and my library: https://adraffy.github.io/ens-normalize.js/test/report-emoji-picto.html -
Emoji ZWJ sequences according to my library: https://adraffy.github.io/ens-normalize.js/test/report-emoji-zwj.html -
All emoji are now on this page: Emoji which includes the ZWJ sequences and is compared against Strict IDNA 2003, 2008, current ENS, and my implementation.
-
Merged display name, tokenizer, and resolver into one tool: ENS Resolver
Well, I was just about to post that I had it all figured out, and then I was curious what would happen if I only gave my library UTS-51 rules and no UTS-46 rules (this should be a perfect emoji parser), and I ran into an issue with ZWJ when testing it:
💩💩 => valid
💩{200D}{200D}💩 => invalid
💩{200D}💩 => valid, but different than above
// invisible poo joiner!
// note: these are separate and already registered:
😵💫 = {1F635}{200D}{1F4AB}
😵💫 = {1F635}{1F4AB}
// and even weirder, since "1" is an emoji
// this is also valid:
1{200D}1
I don’t see anyway of differentiating emoji_zwj_sequence (legal ZWJ sequences) from whats called the RGI_Emoji_ZWJ_Sequence (recommended for general interchange) without pinning the allowable sequences to a whitelisted set of permutations: https://adraffy.github.io/ens-normalize.js/build/unicode-raw/emoji-zwj-sequences.txt
Additionally, how should we treat deliberately text-styled emoji like 💩︎ = 💩{FE0E}?
// note: FE0E and FE0F are ignored
// (A) these should be the same
// (text styling without a joiner)
// each is 2 glyphs
😵︎💫 = {1F635}{FE0E}{1F4AB}
😵︎💫️ = {1F635}{FE0E}{1F4AB}{FE0F}
😵💫︎ = {1F635}{1F4AB}{FE0E}
😵︎💫︎ = {1F635}{FE0E}{1F4AB}{FE0E}
// (B) these should be the same (ZWJ sequence)
// but different from above:
// each is 1 glyph
😵💫 = {1F635}{200D}{1F4AB}
😵️💫 = {1F635}{FE0F}{200D}{1F4AB}
// but with deliberate text styling,
// the ZWJ sequence is supposed to terminate!
// (how these render varies per platform)
(1) 😵︎💫 = {1F635}{FE0E}{200D}{1F4AB} => technically invalid
(2) 😵︎💫️ = {1F635}{FE0E}{200D}{1F4AB}{FE0F} => technically invalid
// this one is okay, no joiner
(3) 😵︎💫︎ = {1F635}{FE0E}{1F4AB}{FE0F} => valid
// depending on the Unicode implementation,
// the (1) edits as either:
(Edit1) [text-styled 1F635] + [200D] + [1F4AB] // 3 glyphs
(Edit2) [text-styled 1F635 + 200D + 1F4AB] // 1 glyph
// (Edit1) and (Edit2) should correspond to (A) or (B) above
If we use the RGI_Emoji_ZWJ_Sequence whitelist, this problem is solved because no text-styled emoji appear in those sequences. Which would imply that text-styled emoji terminate, and are equivalent to their unstyled or emoji-styled versions: 💩︎ == 💩️{FE0F} == 💩(default style).
Edit: I believe my latest version gets everything correct w/ the exception of not knowing which emoji/characters should be enabled/disabled. It correctly handles the examples above.
Characters that should probably change:
-
Currency symbols:
$, ¢, £, ¥, €, ₿, ...These are disallowed, they should be allowed. -
Checkmarks:
❌❌︎🗙🗴🗵🗶🗷✔️✔🗸🗹These are allowed, they should be consolidated. - Negative Circled (Serif vs San-serif): ❻ ➏ these are allowed, they should be equivalent.
- Double vs Single Circled Digits: ➀ vs ⓵ these are allowed, they should be equivalent.
-
Emoji Tags:
🏴 1F3F4 E0067 E0062 E0065 E006E E0067 E007F: these are allowed, they should be ignored as they hide arbitrary data.
Reasonable but Non-RGI ZWJ Sequences:
-
🤼♀️ Women Wrestling Emoji
1F93C 1F3FB 200D 2642
Edit: it appears this is just missing skin color modifier -
👩👩👶👦 Family: Woman, Woman, Baby, Boy Emoji
1F469 200D 1F469 200D 1F476 200D 1F466
Edit: here is Microsoft’s solution: Avalanche of New Emojis Arrive on Windows - etc.
Not sure:
- Variations of this guy:
༼つ◕o◕༽つ,ಠ‿ಠ,└།๑益๑།┘ - Blocks:
▁▂▃▄▅▆▇█If these are allowed, why is_disallowed? And what’s this?🗕 - Math Symbols: many seem very cool and unique, but need individually reviewed.
- Abstract shapes
These lists are incomplete.
Edit: I’ve computed the 75 ZWJ sequences that are non-RGI but show up on emojipedia as JSON. I’ve also included them into the Emoji report.
4 Likes
I respect you! I want to resemble him.
2 Likes
What if we do limit it to the whitelisted set? We can expand the set over time without fear of breaking existing names.
I assume by ‘ignored’ you mean they should normalise to the non-tagged version?
Underscore should not be disallowed, I think. It’s theoretically disallowed in DNS, but in practice is used for a bunch of special-purpose stuff (dmarc, SPF etc).
1 Like
Yes.
After some thought, the presence of an emoji tag sequence should simply terminate the emoji parsing, rather than consuming the tag and ignoring it. The tag sequence would then be processed (and rejected) by IDNA 2008. Ignoring is bad because you need to differentiate Flag from Flag+TagSequence since Flag could combine with something else.
There are only (3) RGI tag sequences in the Unicode set (each following a black flag emoji.) Maybe they should be whitelisted, as 🏴.eth is currently owned (but vulnerable to spoofing on nonsupporting platforms as the tag sequence renders invisibly.)
So the whitelist logic would be:
SEQ = list of allowed complete sequences (3 RGI)
ZWJ = list of allowed ZWJ sequences (1349 RGI + 0-75 non-RGI)
- Find the longest SEQ that exactly matches the characters.
- If it exists, produce an emoji token and goto 1 (this handles the flag + tag sequences)
- Parse the characters according to UTS-51, where ZWJs can join if they form a whitelisted sequence.
- If an emoji was found, produce and emoji token and goto 1.
- Parse the character according to UTS-46 and goto 1.
With this logic, an unsupported ZWJ sequence will terminate before a ZWJ, which will then go through UTS-46 and get rejected by ContextJ. An unsupported SEQ sequence is just parsed normally by UTS-51 and UTS-46 (and likely rejected.)
I updated my library to support this logic. I also whitelisted the 3 RGI tag sequences and added some non-RGI ZWJ sequences as a test.
1 Like
Is this tied into why pfps don’t display right on emoji domains even when they are set with an avatar to display? The avatars don’t display I noticed
1 Like
Can you provide a specific example?
It’s taking me longer than expected to review all of the Unicode characters.
To solve the emoji issue in the short term, I’ve built another variant of my library which I’m calling compat, which uses the current ENS rules (IDNA 2003 w/compat) but uses UTS-51 emoji parsing and my safe modifications (CheckBidi, ContextJ, ContextO, SEQ and ZWJ whitelist, enable a few additional emoji, enable underscore, disable alternative stops.)
Here is an updated report using this library. I’ve also included it into the emoji report.. The errors are almost exclusively names that are obviously malicious. There are 14 bidi errors.
This library is available on npm as @adraffy/ens-normalize. To access the compat build, use:
import {ens_normalize} from '@adraffy/ens-normalize/dist/ens-normalize-compat.js';
let norm = ens_normalize('rAffy💩️.eth'); // throws if invalid
If anyone is adventurous, please give this a test. It should be a straight upgrade relative to existing libraries.
The library is 37 KB. It includes its own implementation of NFC (16KB). Once I figure out why the standard JS implementation is wrong, I can potentially drop this from the payload. Additionally, if the community decides the CheckBidi isn’t necessary, that saves another 5KB.
I’m reluctant to adopt two changes in normalisation in a row. What are you reviewing all unicode characters for right now, and how long do you anticipate it taking?
My goal above was simply to release something that could be used today and possibly get some developer feedback. I believe the functionality of the library is correct, I just don’t what features/characters should be enabled/disabled. I didn’t want to prevent anyone from experimenting with it, and be stuck with my opinionated incomplete whitelist.
Compat is essentially the least-strict version possible. Any names it rejects are a consequence of correct emoji parsing (or the build settings above.) I figure all additional changes (that breaks registered names) requires community input.
-
The trade-offs for CheckBidi are: an increase in implementation complexity and a strict reduction in reachable names. I think this is good for the end user. One mixed-bidi use-case are a few of those Unicode creatures:
༼つ◕o◕༽つwhich is likely by accident. Whereassatoshi܂seems malicious. Additionally, since I hoist emoji out of this validation, emoji correctly mix with RTL labels. -
The trade-offs for Context checks are: an increase in implementation complexity that both enables and disables names. I think this is good for the end-user as it lets various languages to be represented accurately (allows ZWJ where appropriate) and moves some script-specific ambiguities. This is part of UTS-46.
-
The trade-offs for Combing Marks are: an increase in implementation complexity and a strict reduction in names. I don’t think I’ve seen this error in a registered name. This is part of UTS-46.
-
The trade-offs for reducing the label separators to just period are: reduction in implementation complexity. I think this is good for the end-user as the other stops seem malicious. Also being able to split an unnormalized name into labels on just period is a nice property to have. I think you (Nick) agreed earlier in this thread. This is different than UTS-46 but matches EIP-137.
The rest is just dealing with IDNA 2008 being far stricter than 2003.
The emoji and pictographs are all in the emoji report. I’ve been working through the characters that exist in registered names but are invalid according to IDNA 2008, which usually involves going on a tangent to investigate the character and its neighbors. I’ve also been looking at existing homoglyph attack research for ideas.
My plan was to create a similar report to the emoji one, which shows various categories of Unicode under the different build versions, where ranges get condenses to keep it manageable.
An potential idea for how to allow these strange glyphs is to create a “safe” charset, that can’t co-mingle with the exotic glyphs. For example, allow ༼つ◕o◕༽つ but disallow ༼つ◕o◕༽つa because “a” would be safe. The obvious negative would be the increase in implementation complexity.
1 Like
I investigated the NormalizationTest issue a bit more. I compared my library to Python (unicodedata), Mathematica (CharacterNormalize), and various JS engines (Node, Chrome, Safari, Brave, Firefox) and realized its a total shitshow. My library and the latest version of Firefox are the only ones that pass the test. Pinning NFC to a specific Unicode spec appears to be the right choice.
I made a simple report that compares allowed characters (valid or mapped, minus emoji) between ENS0 (current) and IDNA 2008. I overlaid it with with my current-but-incomplete whitelist so (green = whitelist as-is, purple = whitelist mapped). These are the characters that need review and any input would be very helpful: IDNA: ENS0 vs 2008 Edit: I added the number of times each character shows up in a register name in brackets, eg. § [5], means 5 registered names use this character.
There also is a much larger list (the full disallowed list minus this list) that potentially contains characters that should of been enabled in the first place. However, this list too large for an HTML report. For example, underscore (_).
I added an additional 25K registered labels to the comparison reports. Also, this service displays the last 1024 registered labels with normalization applied: Recent ENS Names
2 Likes
UTS-39 and Chromium documentation discuss some good stuff, but they’re both even more restrictive than IDNA 2008.
UTS-39 references a tool which displays confusables. For example, x vs х is crazy dangerous. It shows up in a 14 registered names so far: some surrounded by the appropriate script and a few that are certainly malicious. Applying a confusable-like mapping might be a good idea but it will brick some names. Some of these are already handled by IDNA 2008.
To reduce implementation complexity, rather then relying on many public Unicode files, ENS could supply a singular table that combines UTS-51 (+SEQ/ZWJ), UTS-46, and UTS-39 which makes implementation relatively straight forward.
Edit: Here is a first attempt at a visualization of the confusables relative to IDNA 2008.

The way to read this is: “o” is a confusable category. There are 75 characters that are confusable with it. According to IDNA 2008, they correspond to 42 separate entities after normalization is applied. The largest group has 14 characters that map to o. The next largest group has 7 characters that map to ه, etc. Groups of one are just shown as a single element (without the count and black arrow) to save space. The color codes match the rest of the reports: green = valid, purple = mapped, red = disallowed.
The scary thing would be any groups that map to similar yet distinct characters. For the image above, 14 map to o (6F) and 5 map to ο (3BF). There’s very little difference between “Latin Letter O” and “Greek Omicron”.
2 Likes
I made some improvements to the Confusables. I also added a visual breakdown of the Scripts, with emoji removed. I also included the name if you hover over a character.
I am currently thinking about a Script-based approach to address homograph attacks, as my attempts to whitelist have not been very successful with so many characters. First, each script can be independently reduced to a non-confusable set. Then, each script can specify which scripts it can mix with. By reducing the problem from all characters, to just scripts that should be combined together, the script-script confusable surface is many orders of magnitude smaller.
A few of the script groupings are too sloppy. So I suggest creating a few artificial categories, like Emoji, Digits (that span all scripts), Symbols (split from Common), etc. and merge a few that get used frequently together (Han/Katakana/Hiragana). Common/Latin/Greek/Cyrillic scripts should get collapsed using an extremely aggressive version of the confusables, so there’s absolutely 0 confusables with ASCII-like characters.
Then, based on the labels registered so far, determine what kind of script-base rule permits the most names. eg “Latin|Emoji|Digits|Symbols” is a valid recipe.
I’ve computed some tallies that show what types of scripts show up in labels using the following process: map each character of a label to a script, aaαa → {Latin,Latin,Greek,Latin} then collect:
- By Sequence of Scripts (Duplicates Removed) → “Latin,Greek,Latin”
- By Sorted Set of Scripts → “Greek,Latin”
- By Each Script → “Latin” and “Greek”
For the sorted case, you can see most labels aren’t that diverse:
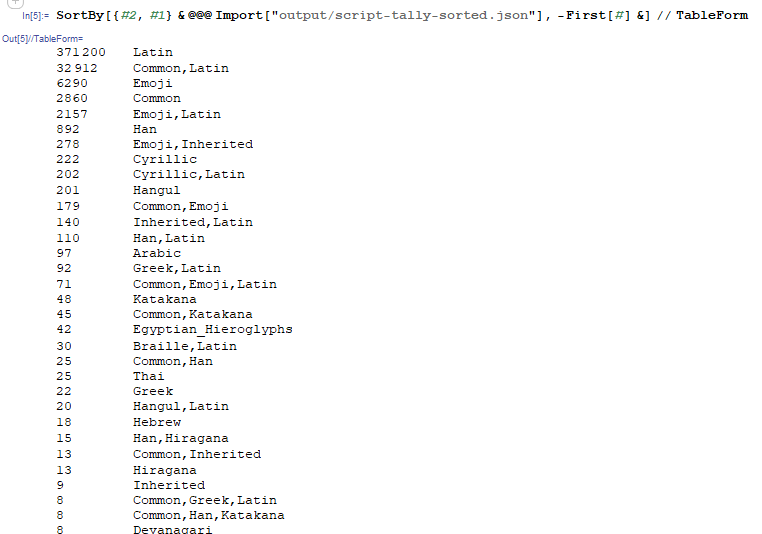
Since 371K labels solely use the Latin script, I think starting with Emoji, Digits (0-9) and Latin (A-Z) and building up, using the confusable mapping to allow more characters, until all of those names are accepted is a good starting point. And then grow from there.
1 Like
I have nowhere near the expertise and knowledge that you do with this, but I have a question: would it be useful to disallow any names ending or beginning with ZWJ, plus disallowing consecutive ZWJ in name?. It seems like this would get rid of a lot of scam names or cut them way back?
So the rule would be a name can’t begin or end with a ZWJ or have more than one ZWJ within the name (I’m assuming consecutive ZWJs aren’t used for any words in other languages or in so-called ASCII art). Is this thinking in the right direction or helpful?
1 Like
Thinking about it further, I think this might solve all the issues for emoji domains with the addition of one rule. The additional rule being to disallow character-ZWJ-character-ZWJ-character… that can’t be a pattern for legitimate emoji domains. In other words, every other character can’t be a ZWJ.
So, the rule is for emojis that 1) the name can’t begin or end in a ZWJ, 2) no consecutive ZWJ and, 3) no alternating ZWJs with one character in between them. I think those rules restrict emoji domains to only legitimate ones. Unsure if this is useful…
EDIT: Rule 3 is inaccurate, there are many single glyph emojis that are 3 or 4 emojis combined and do use every other character as a ZWJ. So strike rule 3
1 Like
In ens-normalize.js, ZWJ are only allowed inside whitelisted UTS-51 emoji sequences and inside ContextJ which permit it between or following a few characters.
Technically, UTS-51 allows arbitrary-length sequences of ZWJ, but many of those do not correspond to a single glyph and indistinguishable, which is why a whitelist is required.
For example, 💩💩.eth = 1F4A9 200D 1F4A9 fits your rules and is valid UTS-51 but invalid in ens-normalize.js
Another example would be 😵💫😵💫😵💫.eth vs 😵💫😵💫😵💫.eth which can only be distinguished by ZWJ placement.
I would consider the ZWJ inside emoji solved, although I’m open to ZWJ sequence recommendations (Unsupported Set from Emojipedia), eg. Microsoft supports a much wider set of family permutations.
The 3 ContextJ allowances are here but I never received any input whether it was worth the extra complexity.
I believe most libraries that are currently in-use allow both ZWJs anywhere, as they are permitted in IDNA 2008 (typically under the assumption that ContextJ is active). They’re actually disallowed in IDNA 2003 (they are deviations) but were permitted to enable complex emoji.
The two lists I’m using are:
1 Like
It looks like ENS will have to whitelist new emoijs when they come out, I’m wondering if ENS will end up actioning them off (outside of the normal way) as it seems like the only type of whitelist where new characters are coming out that are widely used and universally recognized (emojis = pictographs).
Thanks for sharing those links