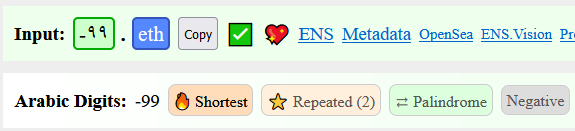
My question is: was this the best outcome? Should we map all the extended digits for consistency? Or disallow them all instead? From earlier discussion – (oh that was you Octexor), we decided to map just the ones that were pixel identical.
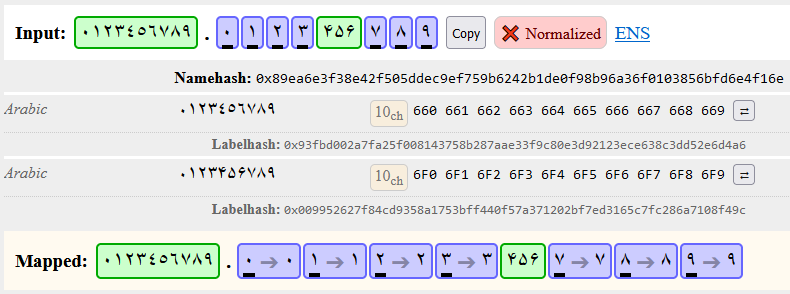
Yes, I applied this change. Please let me know if there are other issues.