It’s actually a really complicated problem. It seems simple, but there are so many cases that are in a gray area for instance that domain lndia.eth looks like india.eth in some fonts, but its actually LNDIA.ETH. Should this be allowed or not. I suggest reading through this post as well. It gets really complicated, ENS Name Normalization.
An interface that makes it possible to easily analyze each character is definitely necessary. Take a look here, https://twitter.com/aoxborrow/status/1479578090061717505
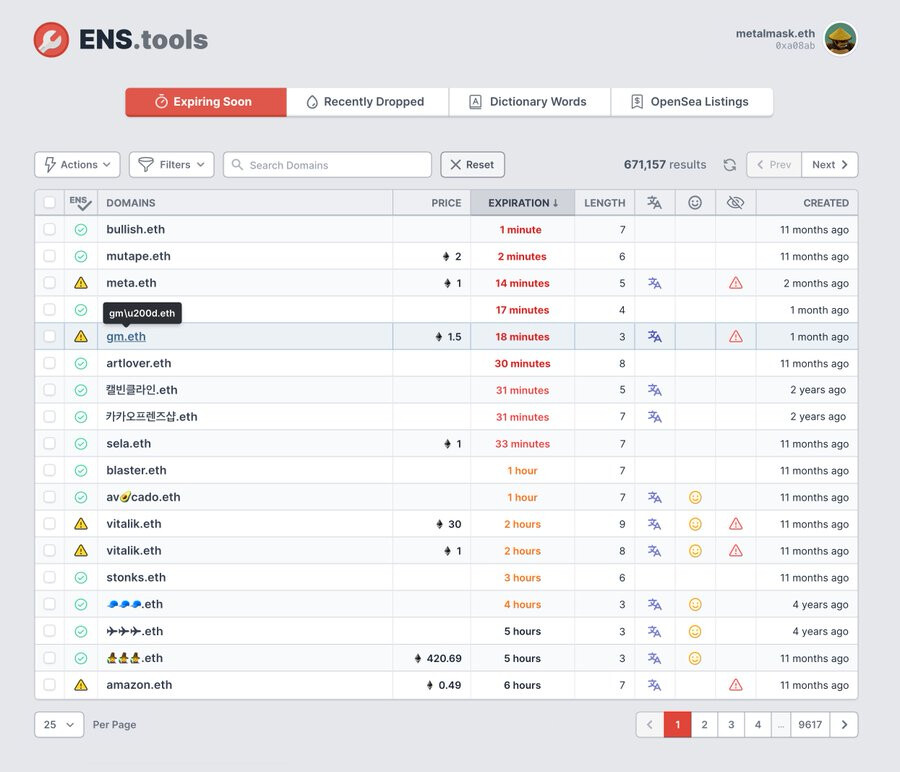
I think a better system would be for a third party marketplace to have a “premium” names filter, wherein the third party can use whatever rules the like to decide which names are “premium”.