Due to how many conflicts this causes with previously registered names, this behavior has been changed in my library and emoji are no longer upgraded. Essentially, ZWJ is optional, which results in multiple names for many emoji.
I think the example Nick shows me was:
-
😵💫😵💫😵💫.eth→0x372973309f827B5c3864115cE121c96ef9cB1658 -
😵💫😵💫😵💫.eth→0x0033AAdE458d0b39Ce0B1Ba2581859F2D5855555
These render identically for me on Windows+Firefox but look separate on my Mac:
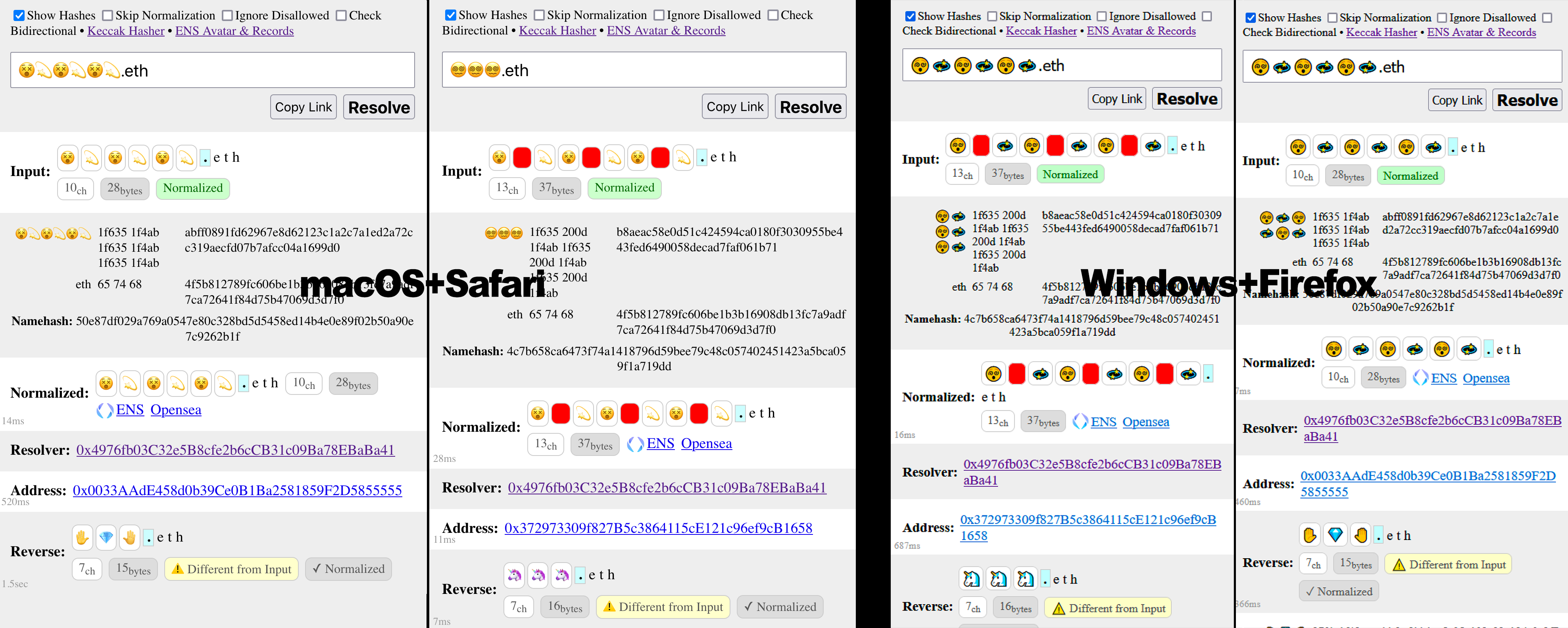
Additionally, if these two examples represent AAA and BBB, then also AAB, ABA, ABB, BAA, BAB, BBA are valid, eg. 😵💫😵💫😵💫.eth