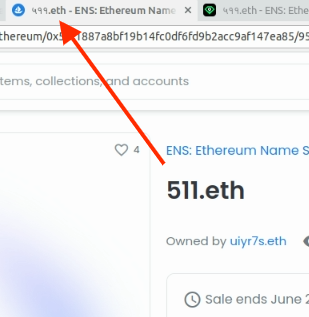
This looks to be something specific to how OS is resolving it, not having to do with current ENS name normalization. On LooksRare the same name does not “convert” to English numerals.
Oddly enough, OS has the right ENS name in the window tab’s title:
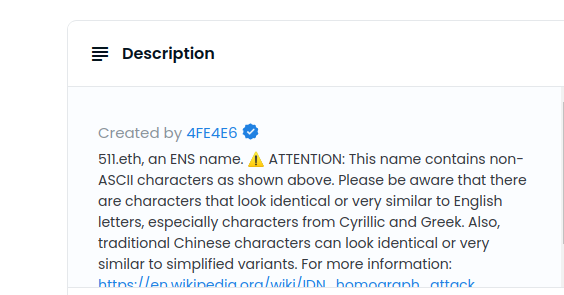
Names with special characters will still show the non-ascii warning. This warning is returned from the ENS metadata service: GitHub - ensdomains/ens-metadata-service
There’s another thread about recent metadata issues specific to OpenSea. It’s here: OpenSea "content not available yet" and missing ENS names