is this hyphen behavior finalized / certain? asking as I am seeing -name --name -name- --name-- name- name-- registrations already and don’t want to enable something on ensvision which is not approved or guaranteed for being allowed in the future.
we try our best to stay in line with ENS registration policies to avoid confusion between the services and what names will be valid but people will start asking about these soon from seeing the registration bots.
I agree, some more information/clarity would be helpful as there are many people now registering domains with characters that are expected to be normalized/validated and some that I believe are not (according to the resolver).
this concerns leading and trailing hyphens, the leading underscore, the dollar sign, the ability to use the euro and pound symbols with letters, the “@” symbol, the ethereum symbol, the bitcoin symbol, and more.
If raffy could provide a list of all the invalid domains along with some information explaining some of the intricate characteristics for different characters/symbols, that would be very helpful to avoid anyone else wasting their eth on invalid domains that will stay invalid after the normalization/validation.
Not my call but I think the registrant should be made aware of the DNS incompatibilities, otherwise, I see no issue.
The only new one is $
Combining marks have been discussed a few times in this thread (#143, #347, etc.)
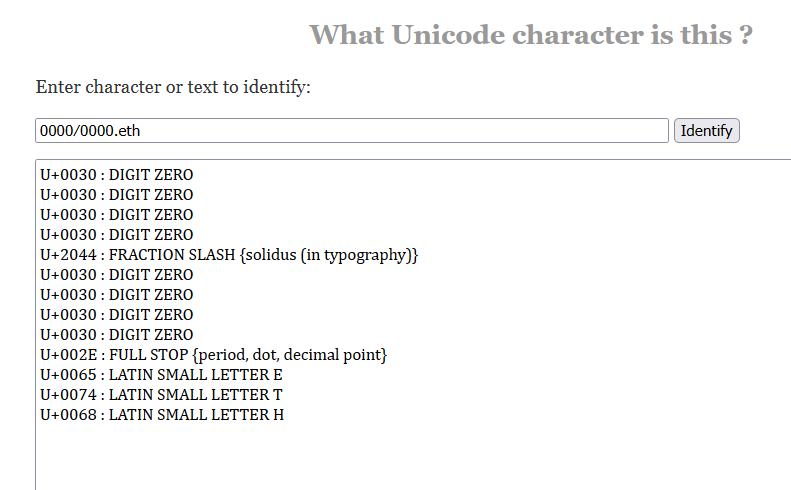
In Unicode 14 Normalization Tests, 61 59A 316 1DFA 316 62 is supposed to normalize to 61 1DFA 316 316 59A 62. The characters 1DFA 316 316 59A are all combining marks. However, 1DFA was added in Unicode 14. In Unicode 13, this string normalizes to 61 316 59A 1DFA 316 62 which is different.
I’m proposing that we limit combining marks to one mark per non-mark character when the name is in NFD form. In other words: no combining mark can touch another combining mark. This avoids any issue with combining mark ordering. If in the future, a previously valid character is deemed a combining mark, the name is invalid (instead of potentially having a new normalization.) The spec should define the explicit list of approved combining marks.
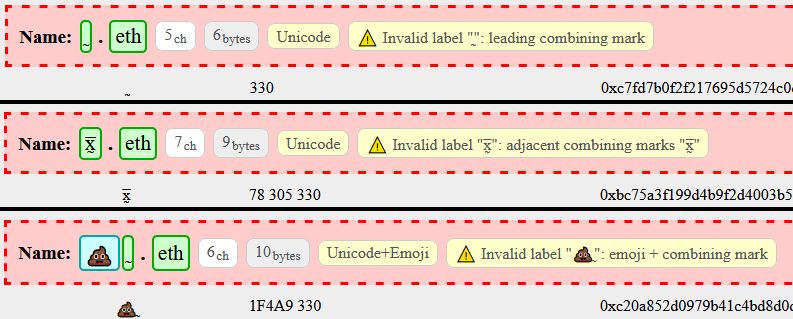
There are 813 names with 2+ combining marks. There is 1 name with a leading combining mark.
While we’re addressing CM, we should also enforce that each label cannot start with a combining mark (this is part of UTS-46 but wasn’t previously enforced) and potentially enforce that a combining mark cannot follow an emoji.
This change would: reduce the confusable attack surface (a large category of spoofs involve carefully placed dot-like combining marks) and greatly expand support for system-level Unicode libraries (otherwise, most normalize implementations will required a versioned Unicode implementation and cannot rely on a system-level function, like the ENSIP warns.)
However, it’s unclear if there are legitimate needs for 2+ combining marks, so I’m looking for input.
/ [2044] is on my “I’m not sure” list. It’s used in IDNA 2003 (and 2008) mapping for fractions (like ½). So if we disallow 2044, we also need to remove 20 mappings.
As of recently, there are about 250 names with 2044.
There’s some Hebrew, Devanagari, Thai names that are collateral damage from the CM change. It’s unclear if these are legitimate names or if they’re just decorated with superfluous CM.
w/r/t Unicode NF support: Node 14 with Unicode 13 now runs the validation tests successfully. Node 12 with Unicode 11 has one 1 error (on a decomposable codepoint that was added in Unicode 13.)
To implement the Emoji + CM rule, the emoji.json now includes single-codepoint default text-presentation emoji (they used to be in chars.json and were considered characters.) Ultimately, I think this is an improvement, because they are emoji, but it potentially breaks the assumption that all emoji are safe – instead, now all emoji of 2+ codepoints are safe.
I also removed the following CMs which appear to be underscore-like: cm-tally.json
320 (x̠) Combining Minus Sign Below
332 (x̲) Combining Low Line
333 (x̳) Combining Double Low Line
347 (x͇) Combining Equals Sign Below
FE2B (x︫) Combining Macron Left Half Below
FE2C (x︬) Combining Macron Right Half Below
FE2D (x︭) Combining Conjoining Macron Below
Also, josiahadams brought up an issue about substring matching, which requires partial normalization. I added some comments to the ENSIP about fragments and included an example which uses ens_normalize_fragment() which is nearly-equivalent to the Processing step in the ENSIP. For example, this would let you prepare the fragment [303 39 FE0F 20E3] and "aa--" (which both fail full normalization.)
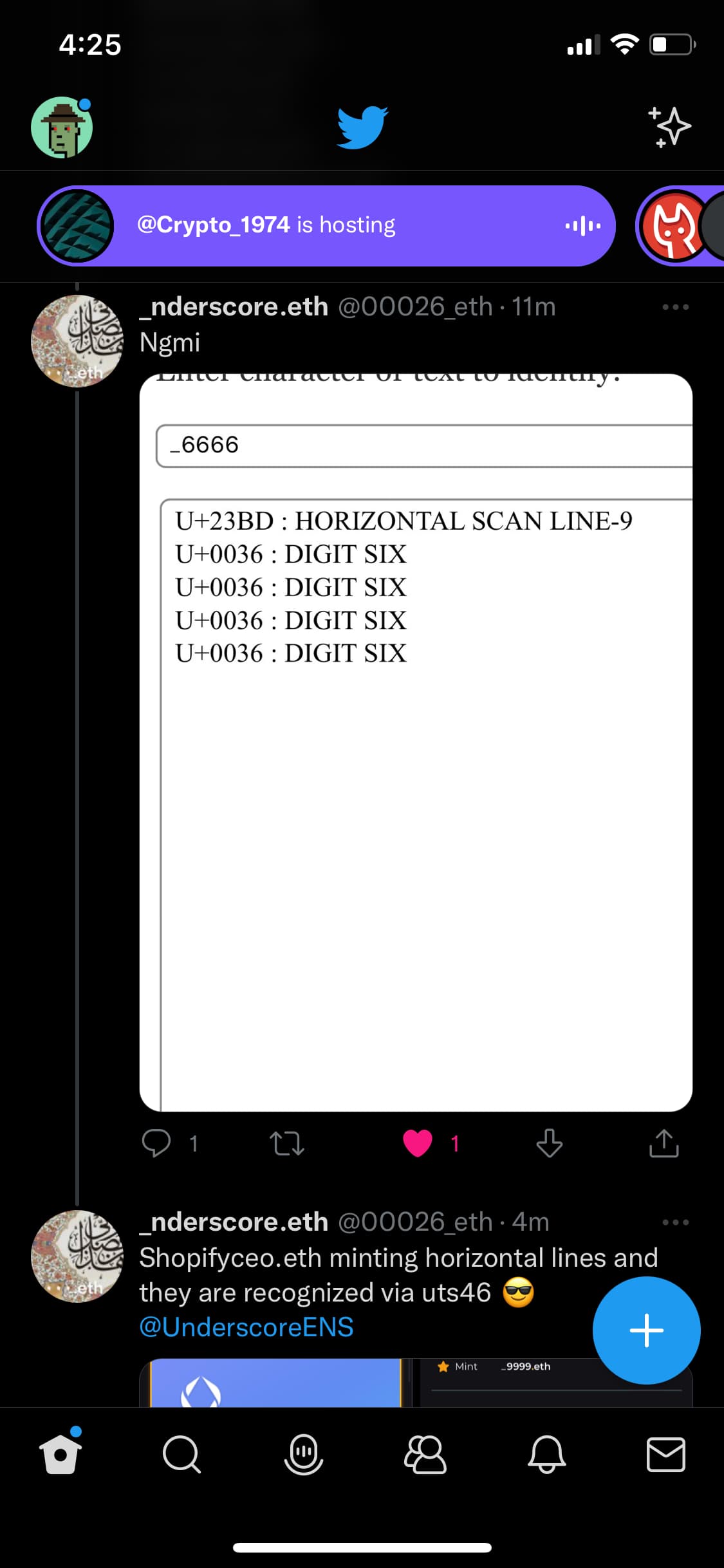
I wasn’t aware specifically of Horizontal Scan Line-# but I’m aware there are many symbols that require opinionated review.
I agree ⎺ ⎻ ⎼ ⎽ ⏤ ⎯ [23BA 23BB 23BC 23BD 23E4 23AF] need mapped to hyphen or disallowed. They should of been part of the hyphen mapping. Edit I say we (1) either disallow all 6, (2) disallow the first 4 and map the last 2 to hyphen, (3) map all to hyphen.
The policy should probably be: there’s one underscore, there’s many things that map to hyphen, or it’s disallowed.
IMO, the following nearby codepoints could be disallowed too:
⎀⎁⎂⎃ — Latin-like
⌿⍀⍳⍸⍴⍷⍵⍹⍺⍶ — APL Letter Like
⍡⍢⍣⍤⍥⍨⍩ — APL + Double Dot
⍫⍬⍭ — APL + Tidle
⍪⍮⍘⍙⍚⍛⍜ — APL + Hyphen/Underscore
⎜⎟⎢⎥⎨⎪⎬⎮⎸⎹⍿ — Vertical Bar
aa⏜aa⏝aa⏞aa⏟aa⏠aa⏡aa – Rotated Brackets (ignore the a’s)
I mapped all 6 of those characters to hyphen (option 3.) While it’s best to disallow characters so they can be revisited later (mapping should be used sparingly), I see no future for alternative hyphens and mapping is much better than the alternative.
I left the others unchanged. They’re low frequency usage at the moment JSON.
The latest version of ens_normalize.js includes NF 14.0.0 ending any Unicode issues. I was able to run 100% validation tests (unmodified) on Node 11 (which is on Unicode 11.) I also removed globalThis.atob() dependency (h/t makoto)
There’s now an ens_emoji() function which returns all of the emoji sequences.
I was incorrect here. There are some confusable emoji that eventually need to be reviewed regarding if some kind of warning is appropriate:
🚴♂🚴🏻🚴 Gender:[1F6B4 200D 2642] vs Skin:[1F6B4 1F3FB] vs Singular:[1F6B4]
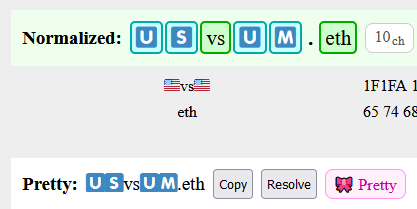
🇺🇸 🇺🇲 US:[1F1FA 1F1F8] vs UM:[1F1FA 1F1F2]
For the flag cases, the beautifier now inserts 200B between regional indicators, which prevents them collapsing into flags. This makes US vs UM obvious and works for all similar flag-related issues.
Unicode 15 officially released. I don’t know if we want to include emojis now or wait until there’s platform support (I say now that they’re official.) I’ll also check what other differences show up when I switch to the latest Unicode data files.
Platform support takes years, Windows still doesn’t support Unicode 14. I say just include them now so we don’t have to release a new version of our libraries and then get ethers/metamask and everyone else to update again etc.