When/how was it last updated? If it’s no more than a couple of weeks old, that should give us a good idea.
Just to revive the underscore issue - what do you think of only permitting it as the first character? I know that would be a deviation from the rest of the function, which is position-independent, but it would allow service domains etc, without allowing it in arbitrary positions.
Edit: I see a lot of arabic numeral names in the diff-norm list. Is this due to there being two versions of certain characters in different alphabets? Do you know how often both normalisations are registered?
I assume you’re talking about this report? The formatting isn’t the best “eth-ens-namehash-error” means the error only occurs in “eth-ens-namehash”, which is the official implementation.
Few days ago, 1.4M names.
This seems reasonable to me. First single character? Or can there be multiple underscores?
Hey @raffy how long do clients usually take to integrate the updates after release? Say for example OpenSea (assuming it’s using the provided normalisation and not an in-house implementation) - how long does it usually take for them to implement the update? I’m assuming MetaMask will take the lead and implement it asap? Thank you.
Unsure. The JS code is incredibly easy to audit or re-implement yourself. The ref-impl and ens-normalize share the same normalization loop that directly follows the ENSIP processing section. I know there’s a Go implementation. I’m not sure how many other implementations exist. The smart contract route might also be best for user-facing applications.
After thinking about this, it might be better to enforce this through validation.
I computed some additional stats for the 1.4M names:
160 non-trivial (everything else) which looks like hyphens and illegal emoji
Only 4.7% (66819 of 1410818 unique-valid names) are non-basic (/^[a-z0-9.-]+$/ + Valid Emoji) JSON
66808 if basic includes leading hyphen
54927 if basic includes anywhere hyphen
Only 4.2% (60584) if I include single-character text-presentation emoji (non-colored) too
Even less if you include the pictographs (non-colored non-emoji)
The current smart contract incorrectly fails on 197 (0.014%), of which 196 are supposed to be valid. Once NFC is fully implemented, that will be 0 (100% match with reference implementation.)
edit: oops, they’re both in Common. I think they both should normalize but it’s unclear if they’re both safe. The community will have to decide if these or others are confusable and result in an unsafe label. My general feeling is that currency symbols aren’t confusing.
For validation, a validator will determine if this is a confusable based on all the characters in the label, ignoring colored emoji.
The trivial Thai validator is just Thai only.
The smarter Thai validator is probably Thai + Latin + Common - Confusables.
The official confusables restricted to those charsets for Thai looks like this, where the non-green cells require a decision.
Confusables aren’t addressed by my normalization proposal. I encountered too many edge cases while trying to develop a complete confusable-free solution.
My suggestion is that we have hard errors for names (normalization) that use illegal constructions (disallowed characters, illegal emoji, invisible characters, etc.) and soft errors for names that are unsafe/confusable (validation).
This allows the normalization spec to standardize and “unsafe” names still work. We can expand the universe of safe names until nearly all reasonable names are covered. We can start with Alphanumeric ASCII + colored emoji which I claim are safe. If we follow the distribution of registered names, it should be easy to hit 99%+ coverage.
There are a large set of single characters (~2K) that consist of default text-presentation emoji (▶, eg. those that appear uncolored) and non-emoji pictographs (☏️). There’s probably a set of these that are safe to use in any name like colored emoji. However, some of these aren’t unique and require a decision: ❤ [2764] vs ♥ [2665]. On Mac, it appears that some of these already buck the Unicode convention and appear colored (eg. ⏭) whereas ↖ [2196] vs ↖️ [2196 FE0F] does not. Determining which of these are safe covers another 1% of names.
Is there any chance I’ll be getting a refund for these two ens names I haven’t been able to sell or do anything with, or even renue? 🇹.eth and 🇮🇮🇮.eth both done in all emojis. I think it has to do with the first two T’s turning into the flag
Still think you are making a mistake with the hyphen and underscore as I think they are confusables and that is the reason the underscore was stopped in web2, but we have minted out the ‘-#-‘ & ‘#’ names etc etc, so either just wasted some money or now have some very rare single digit names for the price of a 3 character name
Not going to keep going on about it as know my opinion doesn’t count, but I feel
It will come back to bite ENS in the ass in the future
Edit:
Underscores still not working, even in quotation marks
I agree with you that symbols that are normally little used will not be an added value in the ens ecosystem, symbols like: [] >/*+" etc. but hypens and underscores are the mostly used characters in general. For example in usernames and do clearly add value to ens domains/ecosystem. Why are people saying that they are confusable? I mean everyone can see that this _ is een underscore and this - a hyphen. This will 100 percent help with the adoption of ENS. I think that it will be one of the main challenges at the moment/future is adoption and with the use of hypens and underscore we just lower the threshold for newcomers.
People keep falling for approval scams in fake NFT airdrops still. Catering to the lowest common denominator isn’t wise.
This is complicated, and it’s going to remain complicated. Web 2.0 just used ASCII. That’s a nice simple solution for 1984. They did great, and Unicode didn’t even get invented until some years later. What would Web 2.0 be now if Unicode came before domain names?
It took nearly 40 years to stop discriminating against non-English speaking people on the internet with DNS. The ENS is governed in English. I think we should be cognizant of the fact we might actually wield great power over the future of internet usage. Anglo-centrism has made the world a smaller place in some ways, but it is silly to continue on with many conventions that limit us as humans. Confusion is just going to be part of life now. We will just have to deal with getting more knowledgable about how society works.
The people falling victim to elementary scams is not a nice thing to see, but we don’t restrict who you can dial in the telephone system just because elderly people get targeted by scams of confusion, manipulation, and misrepresentation.
Just looked into your domain names, and it seems that you just want to cut off the competition to save your own bag (domain names) since you own lots of names/numbers with hypens. I own zero hyphens and zero underscores domains but my usernames on different platforms includes underscores and hyphens and I see no point in confusing them. Maybe in the future I will create some but I’m good for now with my 999club domains.
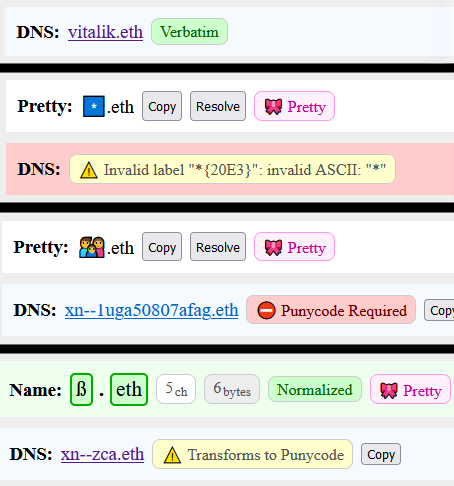
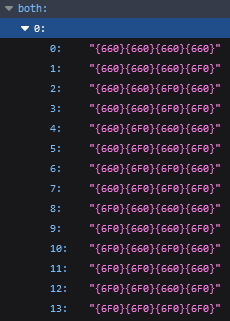


 🇹.eth and 🇮🇮🇮.eth both done in all emojis. I think it has to do with the first two T’s turning into the flag
🇹.eth and 🇮🇮🇮.eth both done in all emojis. I think it has to do with the first two T’s turning into the flag